1.相关概念
1.1模态(Modality)
“模态”(Modality)指的是数据的不同类型或形式
1.2时序数据(Time Series Data)
1.2.1def.
时间序列是以规律的时间间隔采集的测量值的有序集合
1.2.2特征
数据点之间存在时间顺序
时间序列的顺序和时间间隔非常重要
依赖于时间,但不一定是时间的严格函数
1.2.3分类
研究对象
一元时间序列和多元时间序列
时间参数
离散时间序列和连续时间序列
统计特性
平稳时间序列和非平稳时间序列
分布规律
高斯型时间序列和非高斯型时间序列
高斯型时间序列是指数据遵循正态分布的时间序列
1.3文本数据(Textual Data)
1.3.1def.
不能参与算术运算的任何字符,也称为字符型数据。如英文字母、汉字、不作为数值使用的数字(以单引号开头)和其他可输入的字符
1.3.2特征
1、半结构化
文本数据既不是完全无结构的也不是完全结构化的。例如文本可能包含结构字段,如标题、作者、出版日期、长度、分类等,也可能包含大量的非结构化的数据,如摘要和内容。
2、高维
文本向量的维数一般都可以高达上万维,一般的数据挖掘、数据检索的方法由于计算量过大或代价高昂而不具有可行性。
3、高数据量
一般的文本库中都会存在最少数千个文本样本,对这些文本进行预处理、编码、挖掘等处理的工作量是非常庞大的,因而手工方法一般是不可行的。
4、语义性
文本数据中存在着一词多义、多词一义,在时间和空间上的上下文相关等情况。
2时序分析常用方法
2.1描述性时序分析
描述性时序分析又被称之为确定型时序分析,它主要是通过直观的数据比较或绘图观测,寻找序列中蕴含的发展规律。该方法简单直接,所以一般也是时序分析的第一步。
例如,1844 年,德国天文学家海因利希·史瓦贝在 Astronomische Nachrichten 报告了太阳黑子数量的周期性变化规律。其通过系统性的连续观测,发现太阳黑子的爆发呈现出 11 年作用的周期变化。
直观
对数据的要求很高,需要保证数据分布呈现出一定的规律性
2.2 统计时序分析
利用数理统计学相关的原理和方法来分析时间序列
2.2.1 频域分析
假设任何一种无趋势的时间序列都可以分解成若干不同频率的周期波动
2.2.2 时域分析
参照事件发展过程中的惯性,从而通过惯性用统计来描述就是时间序列值之间存在的相关关系,拟合出适当的数学模型来描述这种规律
自回归 AR 模型
ARMA 模型:平稳时间序列分析过程
ARIMA 模型:非平稳序列随机分析过程
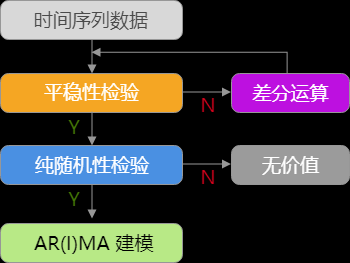
2.3 平稳时间序列检验
2.3.1 严平稳时间序列
序列所有的统计性质都不会随着时间的推移而发生变化
2.3.2 宽平稳时间序列
只要保证序列 二阶矩 平稳,就代表序列稳定
2.4 自相关(Autocorrelation)图
又称之为序列相关。在时间序列中,当我们使用以前的时间步长来计算时间序列观测的相关性时。由于时间序列的相关性与之前的相同系列的值进行了计算,就被称之为自相关
2.5 纯随机性检验
用来判断一个平稳序列是否随机=>纯随机序列是没有任何分析价值的
涉及两个统计量:Q 统计量和 LB 统计量(Ljung-Box)。
但由于 LB 统计量是 Q 统计量的修正,所以业界通常所称的 Q 统计量也就是 LB 统计量。
计算:Python 中,我们可以利用 statsmodels 统计计算库中的 acorr_ljungbox() 函数计算 LB 统计量,该函数默认会返回 LB 统计量和 LB 统计量的 P 值。如果 LB 统计量的 P 值小于 0.05,我们则认为该序列为非随机序列,否则就为随机序列。
2.6 ARMA(Autoregressive moving average)自回归移动平均模型
适用于平稳序列
2.6.1 分类
AR 自回归模型,MA 移动平均模型和 ARMA
AR模型
假设序列包含线性关系,然后使用 $x_{1}$ 至 $x_{t−1}$ 序列来预测 $x_{t}$。其中,$p$ 阶 AR 模型的公式为:
$X_{t}=c+\sum _{{i=1}}^{p}\varphi _{i}X_{{t-i}}+\varepsilon_{t}$
其中,$c$ 为常数项。$ε_{t}$ 被假设为平均数等于 0,标准差等于 $σ$的随机误差值。$σ$ 被假设为对于任何的 $t$ 都不变。$p$ 则代表落后期数。
MA模型
若随机过程 $x_{t}$ 为现在与过去 $q$ 期随机过程 $ε_{t},ε_{t−1},…,ε_{t−q}$ 之加权平均,则 $q$ 阶 MA 模型的公式为:
${x_{t}=\varepsilon _{t} + \theta _{1}\varepsilon _{t-1} +
\theta _{2}\varepsilon _{t-2} + \cdots + \theta
_{q}\varepsilon _{t-q}}$
其中,$θ_{1},…,θ_{q}$ 是参数,$ε_{t},ε_{t−1},…,ε_{t−q}$ 都是白噪声。
ARMA
ARMA 模型一般记作:$ARMA(p,q)$,即为 $p$ 阶 AR 和 $q$ 阶 MA 模型的组合。
建模过程
- 获取序列
- 通过平稳性检验
- 通过纯随机性检验
- 需要确定 $p$ 和 $q$ 的取值。一般来讲,确定二者的取值有 3 种方法,分别是 AIC(Akaike Information Criterion ),BIC(Bayesian Information Criterion ) 和 HQIC(Hannan-Quinn Criterion )。
- 搭建 ARMA 模型
- 模型评估
2.7 差分运算
目的:序列平稳的方法
差分运算实际上是一种从序列中提取确定性信息的方法
1阶差分:对两个序列相邻值(延迟 1 期 时间间隔)作减法运算
$\nabla x_t = x_t – x_{t-1}$
此时,如果对 $1$ 阶差分后的序列再进行一次 $1$ 阶差分运算,就可以记 $∇^{2}x_{t}$ 为 $x_{t}$ 的 $2$ 阶差分,公式如下:
$\nabla^2 x_t = \nabla x_t – \nabla x_{t-1}$
那么,依次类推,对 $p−1$ 阶差分后序列再进行一次 $1$ 阶差分运算,就可以记 $∇^{p}x_{t}$ 为 $x_{t}$ 的 $p$ 阶差分,公式如下:
$\nabla^p x_t = \nabla^{p-1} x_t – \nabla^{p-1} x_{t-1}$
除此之外,如果两个序列值之间延迟 $k$ 期再做减法运算称为 $k$ 步差分运算,记 $∇_kx^t$ 为 $x_t$ 的 $k$ 阶步差分,公式如下:
$\nabla_k x_t = x_t – x_{t-k}$
一般在差分时阶数不宜过大。原因在于差分其实是对信息提取加工的过程,每次差分都会带来信息损失,过度差分会导致有效信息损失而降低精度。一般情况下,线性变化通过 1 次差分即可平稳,非线性趋势 2,3 次差分也能变得平稳,一般差分次数不超过 2 次。
2.8 ARIMA 介绍及建模
非平稳
相比于 ARMA 模型中存在的 $p$, $q$ 参数,ARIMA 多了一个参数,那就是使非平稳序列成为平稳序列所做的差分阶数 $d$。所以,ARIMA 模型通常记作:$ARIMA(p,d,q)$。