欢迎使用 WordPress。这是您的第一篇文章。编辑或删除它,然后开始写作吧!
博客
-
论文推荐 | 工业5.0下大语言模型与数字孪生的集成:研究框架、挑战和机遇
感谢导师栽培,本人的第一篇论文。欢迎报考广东工业大学信息物理融合系统(CPS)实验室!
文章信息
论文《Integrating large language model and digital twins in the context of industry 5.0: Framework, challenges and opportunities》于2025年2月被收录于《Robotics and Computer-Integrated Manufacturing》期刊。本文由来自广东工业大学、
英国阿斯顿大学、香港理工大学的Chong Chen, Kuanhong Zhao, Jiewu Leng, Chao Liu, Junming Fan, Pai Zheng共同完成,文章探讨了在工业5.0背景下,将大语言模型(LLM)与数字孪生(DT)技术整合的框架、挑战与机遇,并提出了名为Interactive-DT的整合框架,旨在揭示大语言模型如何有效集成并作用于数字孪生环境的技术路径。
DOI:10.1016/ j.rcim.2025.102982
引用本文:
C. Chen, K. Zhao, J. Leng, C. Liu, J. Fan, and P. Zheng, “Integrating large language model and digital twins in the context of industry 5.0: Framework, challenges and opportunities,” Robotics and Computer-Integrated Manufacturing, vol. 94, p. 102982, 2025/08/01/ 2025.

文章阅读
Integrating large language model and digital twins in the context of industry 5.0: Framework, challenges and opportunities
Chong Chen a, Kuanhong Zhao a, Jiewu Leng b,* , Chao Liu c, Junming Fan d, Pai Zheng d
a Guangdong Provincial Key Laboratory of Cyber-Physical System, Guangdong University of Technology, Guangzhou 510006, PR China
b State Key Laboratory of Precision Electronic Manufacturing Technology and Equipment, Guangdong University of Technology, Guangzhou 510006, PR China
c College of Engineering and Physical Sciences, Aston University, Birmingham B47ET, UK
d Department of Industrial and Systems Engineering, The Hong Kong Polytechnic University, Hung Hom 999077, PR China
摘要
本文探讨了在工业5.0背景下,将大型语言模型(Large Language Models, LLM)与数字孪生(Digital Twins, DT)技术相结合的框架、挑战与机遇。研究首先回顾了文献,分析LLM在数字孪生中的作用和功能。随后,提出了一种名为Interactive-DT的框架,用于实现LLM与数字孪生的有效整合,并详细阐述了模型在不同层级的作用和功能。最后,论文指出了当前研究中的空白和未来整合大型语言模型与数字孪生的前景。研究表明,大型语言模型有潜力提升数字孪生的构建和运行能力,增强云计算与边缘计算的协作,以及提高数据分析水平,从而推动符合人性化及可持续性原则的高效工业实践。
关键词
大语言模型、数字孪生、工业5.0、智能制造
1. 引言
本文首先介绍了工业5.0的概念及其在制造业中的重要性。工业5.0强调将人类的创造力与先进技术(如人工智能、物联网和机器人技术)相结合,旨在提高生产效率和可持续性,同时关注工人的福祉和个性化消费体验。在这一背景下,数字孪生技术成为实现实时优化的关键工具。DT通过创建物理实体或过程的虚拟模型,能够实时分析、监控和控制物理系统,从而提升运营效率、减少浪费和能源消耗,推动工业生态系统的可持续发展。
然而,尽管DT在工业4.0和5.0中展现出巨大潜力,但其在大规模系统中的构建和操作仍面临诸多挑战,如数据传输、分析和高级应用的复杂性。这些问题可能通过引入大语言模型得到解决。LLM凭借其先进的自然语言处理能力,能够在DT环境中提供更直观的交互界面,帮助操作人员更好地理解和利用DT生成的数据。此外,LLM还可以通过处理非结构化数据,提升DT的预测分析能力,生成基于实时数据的报告和建议,从而支持更有效的决策。
本文的研究旨在探讨LLM与DT在工业5.0背景下的有机融合,提出一个名为Interactive-DT的框架,揭示LLM如何有效融入DT环境并发挥其功能。文章首先通过文献综述分析了LLM在DT中的角色和功能,随后提出了一个技术路径框架,详细阐述了LLM在边缘层、DT层和服务层的作用。最后,文章讨论了LLM与DT集成的研究挑战和未来前景,强调了LLM在提升DT能力、促进云边协作和复杂数据分析方面的潜力,推动工业实践向高效、以人为本和可持续的方向发展。
2. 文献综述
本文的文献综述部分覆盖了工业人工智能、数字孪生技术及其在智能制造业中的应用,特别是大型语言模型的发展和其对工业5.0的影响。首先,文章探讨了如何利用工业人工智能推动向工业5.0的过渡,包括协同机器人、数字孪生、增强现实等技术的综合运用,并强调了这些技术在智能制造中的重要作用。文献回顾不仅关注当前的技术进展,还指出了未来研究的方向,为理解现有成就与未解难题提供了基础。
接着,文章深入讨论了数字孪生技术的应用现状和发展趋势。例如,在产品设计、开发及维护过程中,DT能够模拟物理系统的运行情况,提供实时监控与优化功能。具体而言,通过构建高保真度的虚拟模型,DT可以实现从设计到制造再到回收的全流程管理,极大提高了生产效率和产品质量。此外,作者还分析了基于知识图谱的制造过程规划最新进展,以及如何将LLM与知识图谱结合以提升决策支持系统的能力。
进一步地,文献综述考察了LLM在不同领域的应用潜力,如公共部门决策制定中的建模与仿真、法律领域的大规模调查以及制造业中的人机协作。特别是在制造业中,LLM不仅能辅助生成协作设计方案,还能通过错误辅助微调提高制造精度。同时,文献中也提到了LLM在处理幻觉、偏见和推理速度方面的挑战,并提出了相应的缓解策略,如利用代理促进DT与LLM之间的更紧密合作。
此外,文章还回顾了关于大型语言模型可解释性的研究,指出尽管LLM在许多领域展示了强大的能力,但其内部运作机制仍不透明,这限制了它们在某些需要高度可靠性的场景下的应用。因此,提升LLM的可解释性成为了关键的研究方向之一。文章还介绍了几种新兴的方法和技术,如低秩适应、联邦学习框架等,旨在克服现有挑战并拓宽LLM的应用范围。
最后,文献综述部分总结了多个重要研究发现,并对未来的研究方向提出了展望。例如,如何将LLM更好地融入数字孪生体系,以实现更加智能化的预测性维护;如何利用LLM提高制造过程的知识共享和认知助手的功能;以及如何在保障数据安全的前提下,利用边缘计算增强云边协作等。总的来说,本文的文献综述不仅梳理了现有的研究成果,也为后续研究奠定了理论基础,强调了跨学科合作的重要性,对于推动工业5.0背景下的人工智能和数字孪生技术的发展具有重要意义。
3. Interactive-DT框架
文章首先提出Interactive-DT框架,旨在解决大型语言模型(LLM)和数字孪生(DT)在工业5.0背景下集成的挑战,通过增强两者之间的互动来优化制造过程中的操作、维护和控制策略。Interactive-DT不仅促进了DT内部不同组件间的交互,还增强了DT与人类操作员之间的互动,特别是在工业5.0环境中的人机协作。
Interactive-DT架构由四个相互连接的层次组成,共同作用以实现更高效的工业流程。首先是资产层,负责数据采集和初步处理,包括传感器、执行器、机器、RFID标签和边缘设备等组件,确保原始数据能够被有效地收集并进行初步分析。接下来是边缘层,利用边缘计算技术,提供本地数据存储、无线网络和计算节点等功能,并且在此层中,LLM辅助进行上下文数据注释、决策支持以及DT代理间交互,这极大地提升了数据处理的速度和准确性。
第三个层次是数字孪生层,它作为物理系统与虚拟环境之间的高保真链接,对于设计、制造、物流和维护中的无缝数据融合至关重要。此层通过数字映射和更新集成了物理数据,而LLM则充当智能代理,利用知识图谱进行深度学习和数据处理,进一步提升系统的智能化水平。最后是服务层,涵盖了产品生命周期管理、用户友好报告生成、未知故障模式预测及复杂系统操作工作流优化等功能,使得整个系统不仅能高效运行,还能为用户提供定制化的服务和支持。
此外,文章指出,将LLM与DT相结合可以创建一个互补系统,充分发挥两种技术的优势。例如,DT能够在虚拟环境中仿真和验证LLM提供的建议,帮助识别和纠正错误,避免直接实施有缺陷的决策。同时,当DT检测到LLM推理结果中的偏差时,仿真反馈可用作训练数据,推动LLM的迭代优化。这种集成不仅解决了单独部署LLM或DT时面临的局限性,还显著提高了工业流程的效率和准确性。
.webp)
图1 Interactive-DT框架结构图
在Interactive-DT框架下,文章详细探讨了大型语言模型如何在数字孪生的构建与运行过程中发挥关键作用。首先,在数据获取和集成阶段,来自传感器、物联网设备和其他制造环境中的多源数据被收集并确保反映物理系统的准确状态。然而,这些数据往往格式各异,需要进一步处理才能用于DT建模。LLM凭借其解读不同格式数据的能力,如文本报告和日志数据,将其转换和整合为统一数据库,从而支持后续分析。
随后,LLM在DT的仿真与优化中也扮演重要角色。通过先进的数据处理、建模和仿真技术,LLM有助于实现从数据采集到应用及用户交互的整个流程的高效集成。例如,在产品设计阶段,LLM-DT结合能够促进创新设计,增强客户参与度,并提供个性化建议;而在制造过程中,LLM-DT可以实时分析收集的数据,优化动态工作流,提高生产效率,并精确预测需求以优化生产计划。
此外,LLM还参与到部署阶段,提供部署方向并创建脚本简化过程,同时保证安全性。它还能根据实际需求选择合适的部署选项,包括云端、本地和边缘计算,这对提高效率和降低成本至关重要。最终,LLM不仅确保了操作数据的准确性,还生成详细的可视化报告,帮助用户理解DT性能,做出明智决策,并创建全面的文档资料,使用户能有效地操作和利用DT的功能。通过这种方式,LLM显著提升了DT在整个生命周期管理中的效率和效果。
.webp)
图2 LLM 赋能数字孪生构建与运行
随后,在Interactive-DT框架下,文章探讨了LLM如何增强DT在工业生产中的应用,特别是在云计算和边缘计算协作的背景下。随着工业5.0的到来,对实时监控和优化物理资产的需求日益增长,而处理大量多源数据的需求也变得至关重要。边缘计算因其低延迟、高带宽和本地化处理能力成为了DT不可或缺的一部分,尤其适合需要快速且精确处理的数据密集型场景。
此部分详细介绍了LLM如何通过多种方式优化云边协作。首先,在边缘计算层面,LLM能够自动执行数据预处理任务,如数据标注、过滤和清理,有助于机器学习算法更好地训练模型。同时,它还能减少模型的计算和存储需求,从而提升边缘节点上机器学习算法的性能。其次,在云计算方面,LLM可以分析存储在云端的大规模数据集,识别模式、趋势和异常,提供系统行为和性能的宝贵见解。此外,LLM还支持分布式模型训练,利用多个边缘设备和云资源进行大规模数据集上的训练,确保模型的准确性和泛化能力。
最后,文中强调了云边交互的重要性,并指出LLM在此过程中扮演的关键角色,比如通过优化资源分配来提高效率。通过这些方法,LLM不仅提升了DT的操作效能,还在降低成本、增强决策支持以及实现更高效的工业流程优化等方面发挥了重要作用。这为工业4.0向工业5.0的过渡提供了坚实的技术支撑。
.webp)
图 3 LLM赋能数字孪生中的云边协同
紧接着探讨了LLM如何通过强大的数据分析能力增强数字孪生系统的功能与效率。先进数据分析被定义为利用复杂的机器学习和可视化技术来挖掘数据背后的价值。LLM与DT的结合不仅促进了这种高级分析,还提高了数字孪生系统处理复杂问题的能力。
首先,LLM能够在数据生成、对齐及融合方面提供支持。例如,在数据对齐过程中,LLM确保来自不同来源的数据(如图像或传感器读数)能够正确同步,并且时间序列数据能按照发生时间准确关联,这对于需要实时监控和数据分析的应用至关重要。此外,对于涉及空间数据的应用,LLM可以助力不同空间尺度和分辨率上的数据点对齐,确保数据的一致性整合。
进一步地,LLM通过强化学习策略的发展以及从文本数据设计奖励函数,促进了有效强化学习的发展,使DT能够根据物理系统的反馈动态调整操作和维护策略。同时,LLM还可助力于将物理知识嵌入到模型中,并设计损失函数,这对于开发鲁棒的物理信息机器学习模型至关重要。此外,LLM通过引入小样本和多模态学习,增强了分析能力,使得DT可以以最少的训练处理多样化的复杂数据集。LLM与DT之间的协同作用可用于实时数据分析和决策制定,极大地提升了数字孪生系统的响应速度和准确性,从而推动了工业实践向更加高效、人性化及可持续的方向发展。
.webp)
图 4 LLM赋能数字孪生中的数据分析
同时,文章探讨了LLM如何显著增强数字孪生技术的应用范围与效能。数字孪生通过提供物理系统的虚拟模型,实现了对系统进行监控、仿真和优化,已在产品设计、制造、维护及回收等多个领域展示了其革命性影响。将LLM融入数字孪生框架,不仅提升了自然语言交互能力,还增强了实时数据处理、预测性维护以及自动化文档生成等功能,从而推动工业系统向更加智能和响应迅速的方向发展。
特别是在产品设计阶段,LLM与DT的结合使设计师能够利用自然语言处理功能更直观地与系统互动,实现创新设计的同时提高客户参与度,并提供个性化建议和反馈。在制造过程中,LLM-DT组合能够分析实时收集的数据,优化动态工作流,提升生产效率并准确预测需求,从而优化生产计划。进入维护阶段,LLM-DT可以通过分析传感器数据和操作日志来诊断问题,提供交互式故障排除方案,进行根本原因分析以识别设备故障,并提出预防措施。而在回收阶段,LLM-DT可以优化供应链管理,高效分配资源,改进物流流程,同时分析材料成分和使用情况,提出最佳的回收和再利用策略,促进循环经济的发展。
.webp)
图 5 LLM赋能数字孪生下游应用
4. 挑战与机遇
文章详细探讨了将大型语言模型与数字孪生技术集成到工业5.0环境中的复杂性、潜在问题及机遇。这一部分不仅强调了LLM-DT结合为制造业带来的巨大潜力,同时也指出了实现这种集成所面临的诸多挑战。
首先,文章讨论了LLM的幻觉问题,即LLM可能生成听起来合理但实际上错误或无意义的输出。这对工业应用尤其具有破坏性,因为基于错误数据做出的决策可能会导致操作效率低下、安全隐患以及生产力下降等问题。例如,在设备维护建议方面,如果LLM根据不准确的数据提供维护指导,可能导致不必要的停机时间增加、维修成本上升,甚至引发灾难性的设备故障。解决这一问题的关键在于确保LLM提供的信息的可靠性和准确性,任何偏离事实的数据都可能对各种工业应用产生广泛的负面影响。
此外,偏见的传播也是一个需要关注的问题。由于训练数据集可能存在偏差,这可能导致LLM在决策过程中引入偏见,影响DT的公正性和有效性。同时,快速推理的需求也是工业应用中的一个重要考量因素,特别是在实时监控和优化生产流程时,及时准确的信息处理至关重要。为了克服这些问题,可通过代理促进DT与LLM之间的有效协作,并保证数据转换和交互的准确性。
进一步地,文章强调了以人为本、韧性和可持续性等主题的重要性。这意味着,LLM-DT的整合不仅要考虑技术层面的改进,还需注重提升工业实践的人类福祉、增强系统韧性并推动可持续发展。
最后,文章指出,尽管存在上述挑战,LLM与DT的结合也为工业领域带来了前所未有的机遇。通过提高数据分析能力、支持更加智能的决策制定以及改善用户体验,这种结合能够显著提升工业效率和可持续性。Interactive-DT框架的提出正是为了应对这些挑战,并利用LLM-DT整合的优势,实现更高水平的智能化制造和服务。综上所述,虽然LLM-DT整合面临技术和伦理上的多重挑战,但其潜在的积极影响无疑为未来的工业发展提供了广阔的空间和无限的可能性。
5. 总体结论
大型语言模型和数字孪生的融合对工业5.0中的发展具有重要意义。本文首先回顾了关于LLM和DT的最新研究。然后,提出了一种名为Interactive-DT的框架,用于在工业5.0中集成LLM和DT。同时,探讨了LLM在DT构建与运行、云边协同、高级数据分析和下游应用中的作用。最后,针对幻觉、偏见和推理速度等挑战提出了缓解策略并探讨了潜在的研究机遇,作者希望能对LLM和DT相关的研究人员与从业者提供有益参考。
-

东京游记
我在国内的日音类live抢票大战中屡次拼劲全力仍无法战胜黄牛、科技佬。在大麦抢票更是每次都被盾,等我控制滑块使之恰好露出三个菠萝的之后,迎接我的是满屏的“余票登记”。于是我便抱着试试看的想法抽了烤4th东京场的票,没想到直接就中了s席(后来友人告诉我烤的演唱会一直都很好抽),于是便有了这次东京之旅。
行前准备
还是参考的arisa大佬的现地教程进行的准备。
签证:由于广州领区的签证费用相较于我户籍地的低,我便从广州领区申请的大学生单次签证,按照商家要求的资料进行准备,户籍地不在当前领区的往往额外需要居住证或者在读证明。
钱:本次行程全部为东京周围,蓝绿支付覆盖率很高,故现金我只准备了2w5,8天的行程下来刚好花完。神社往往只收现金,我在各个神社花了不少钱买御守和御朱印,没有计划在神社进行消费的可以再酌情少兑换一些。银行卡的话银联支持的地方较多,一般能用银联的地方也能用蓝绿,不想带太多现金的话建议还是备一张jcb/visa/万事达/运通卡,银联信用卡和所有境外卡组织往往有返现活动,记得报名(运通是在运通卡礼遇小程序,其他卡组织一般是在银行app内)。微信支付可以领取汇率卡,汇率升级到最高后貌似比银行卡返现还要优惠一些。交通卡放在下一部分讲。
交通:地图请用谷歌或苹果,纯血鸿蒙暂且就别用了。小米的手机在使用时可能会出现地图指针方向相反的情况,(我就在第一天晚上下了电车后多绕了一段路,还好索尼手机救我狗命)。
小米谷歌地图箭头反向解决方法
1.清除数据并卸载当前版本谷歌地图
2.安装这个版本https://www.apkmirror.com/apk/google-inc/maps/maps-10-18-3-release/,并打开一次
3.从Google Play更新
交通卡在日本的用途很广,便利店、自动售货机和一些景点的门票、物贩都可以使用。高贵的苹果用户可以直接在钱包申领,可用银联卡增值;日版安卓可以下载谷歌钱包添加交通卡,可用境外卡组织银行卡增值。实体卡有两种,我是在jr秋叶原站外面的机器上办的记名suica卡,所谓记名就是自己随便输个名字,约等于不记名,增值只能用现金。还有一种在机场就可以直接办理的游客卡,有效期较短,余额不退。
Day0: CAN-HND,被小米搞的晕头转向的宾馆寻找之旅
北京时间下午三点从白云机场出发,并在当地时间晚八点落地羽田,下了飞机迎接我们的是摆渡车(ANA你怎么好意思的)。入境流程很快很顺利,但是等行李等了大概半个点。
被小米的反向箭头搞得多走一公里的冤枉路之后,来到了位于浅草的宾馆,我入住的宾馆是支持24小时自助办理入住的。日本有一部分宾馆是不支持夜间办理入住的,预定前请务必确定好行程。
Day1:小肥初探秋叶原
前一日的舟车劳顿使我起床便已经是上午十点,错过了宾馆的免费便餐,也打乱了我预先定好的行程。简单洗漱后上街寻觅食物,初到日本给我的印象便是街道很洁净,柏油路面上说一尘不染有些夸张,但没有大块的垃圾或明显的尘土。宾馆距离浅草寺很近,所以周边就有商店街。本来是想着去一兰拉面的,结果队伍从二楼排到一楼,便从楼下的便利店简单吃点。顺带发现了明治和pjsk的联动活动,买3个明治巧克力可以领取一个文件夹,遂爆买,谷子我留下,巧克力给亲戚孩子当伴手礼,一石二鸟!
东京的街道上鸽子成群结队,空中回荡着乌鸦的叫声。这种鸟类生态和国内有好大不同,在东京的这8天里,我也就只在上野公园看到了麻雀这一唯一其他的鸟类。

吃过早午饭合一的便利店简餐后,我乘坐筑波快线抵达秋叶原。周末的秋叶原在白天是完全的步行街,两端堵死不让车过。扫完货出门已经是傍晚了,下意识地直接过路口才发现“步行者天国”解除了,差点直接转生异世界了.
先去owndays用之前在国内的验光单配了两幅眼镜,人民币900元。owndays自有的镜片立等可取,如果换用尼康的镜片需要等三天,所以行程比较紧的小伙伴记得先去配眼镜。也许是周末,有一位中文店员在这里。但三天后取眼镜的时候他就没在这里上班。
之后便是每一个舞萌痴来到日本的定番:打音击😋

由于打舞萌的人有点多,day1只玩了音击(左上)、中二和我很久之前就想玩而现在已经离线运营的牵手*连接(右图)。游戏自带简中,大陆却一直没有引进😓。nene的大雷一直晃来晃去,搞得我都看不清谱子😍 。
左下是花费50大洋抽的卡在印卡的时候有个西方老外一直在旁边看着。
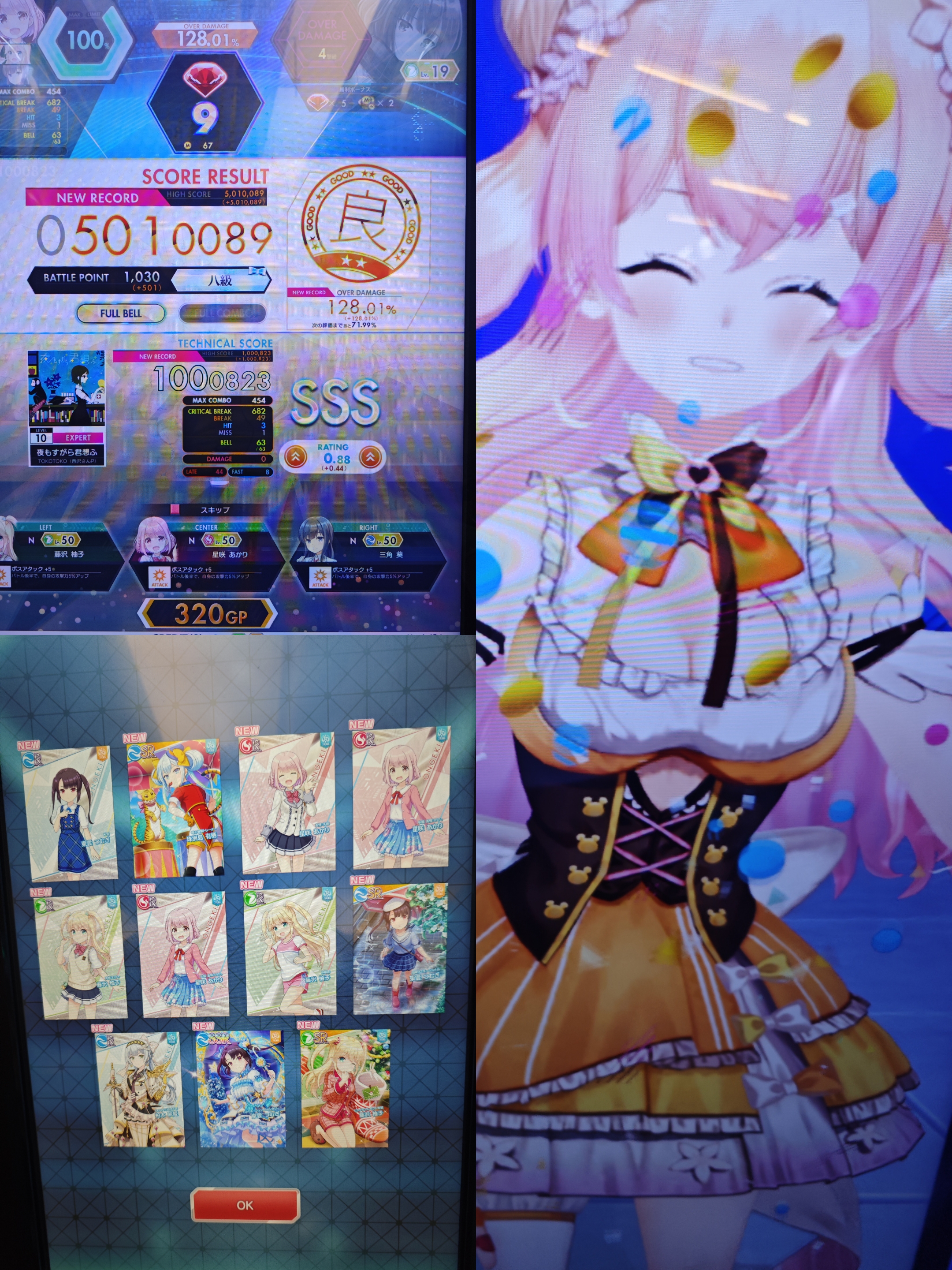
之后便开始各种二手店扫货,个人体感k-books要比骏河屋好逛,地方大、种类齐全、分类明确。骏河屋的空间有些小了,但是时间充足的可以去翻翻筐子,指不定能发现意外惊喜。

在日本正儿八经吃的第一餐是烤肉。东京有很多这样一人食的饭店,对独狼玩家很友好。在国内的想吃烤肉的时候总得找另一个人一块吃,相较于国内一般是在石锅上烤,这家是直接见明火的,掌握不好火候容易烤焦。日本的所有饭店建议在中午吃,会有比较便宜的套餐,总体价格也比晚上便宜。我但凡要是早去半个小时就能免费续饭了。

回到宾馆时间还早,便步行前往浅草寺。从极具日式特色的雷门大灯笼下面进入,是一段大概三四百米的小摊街,夜间这些小店已经关门歇业,露出铁皮门上浮世绘风格的涂鸦。据说浅草寺的签是比较灵的,我抽到了一个末吉。

Day2:MyGO巡礼
第二天起来恰好赶上了早餐的尾巴,恰了五六个小面包和一杯咖啡后便动身前往池袋。日本的公交220円,对比国内1块甚至2块还打折的公交票价着实有点小贵。在一个柏青哥店门口下了车,转乘JR前往池袋太阳城。日本真的到处都是弹珠机店,我在秋叶原也去一家看了看,里面机器光彩夺目,不断用声光刺激着玩家留在机器前。日本之前曾尝试限制这一“合法的赌博”产业,但貌似因为这实在是“百万漕工之所系”最终不了了之。

阳光水族馆
水族馆本身是不错的,这里也是偷摸零和圣爱音看企鹅的地方,但是学偶联动不怎么走心,本质就是来卖周边的。


1楼貌似会周期性地换展,当时在展的是深海生物。此处@平安民警

2楼是浅水和热带动物等,楼顶有企鹅。
![[神奇海螺][对比图生成器][m7hgmohb]](http://img.nozomicloud.top/blog/article/%5B%E7%A5%9E%E5%A5%87%E6%B5%B7%E8%9E%BA%5D%5B%E5%AF%B9%E6%AF%94%E5%9B%BE%E7%94%9F%E6%88%90%E5%99%A8%5D%5Bm7hgmohb%5D.webp)
满天 星象馆
体验很不错!行程安排不怎么紧的迷子推荐来看一看。我出来水族馆后最近的一场是猫星夜,猫的cv是樱井孝宏,mc是松冈,360度的投影身临其境,内容大概是一只猫在夜间会离开城市来到山上,看着天上的星星组合想象出不同的东西:这几个星星连起来像逗猫棒,那几颗星星连起来像是在玩球的猫。配合着特制的香氛,躺在椅子上,忘却外面世界的嘈杂,仿佛回到了那个无忧无虑的童年。那时,我也像这只猫一样,看着满天繁星,一个个地给他们连线,组成各种各样的图案。

啤酒烧烤大电影&烧鸟
从太阳城出来后时间还早,便去GiGO池袋店勤了一会。比起国内把音游机当作引流工具,日本这边大多都是单独拿出来一层为音游玩家服务。世界计划的电影纯纯的粉丝向,剧情没啥爆点,属于看到开头知道结尾那种类型,但是里面有4场手绘live和1个手绘mv,个人感觉诚意还是在的。就是游戏特典这个事感觉sega有点不当人了。
在池袋市民中心附近的鸟贵族吃的烧鸟,店员一开始给我的日文菜单,过一会后发现我是外国人给我换的英文菜单。点的推荐套餐里有一种肉糜捏成的肠,肉本身还可以,但是上面抹的酱实在是太酸了!综合评价不如淄博烧烤。还有这家店是允许店内吸烟的,烟味敏感星人避雷。

Day3:涩谷、八公与大久保
今天的主要行程是把东京都西部的较为知名的几个而我本人不太感冒的几个点位快速过一遍。
上午吃的otona推荐的乌良商店。炸猪排便宜(指50多块钱)大碗,一口咬下去汁水很足。给配了两种蘸酱和柠檬块。

忠犬八公像就在涩谷那个著名路口旁边,从正面合影要排很长的队,我就只从侧面拍了一张。JR站的过街天桥是个不错的免费拍照点位。简单逛了个商场,里面东西着实打不起兴趣,便继续乘山手线前往新宿。

也许是我来到太早的缘故,歌舞伎町一番街和后面的大久保公园都很正常,站街的甚至还没秋叶原和池袋多。风俗店也比想象中的数量要少,评价为比较正常的一条街(晚上不清楚)。在新宿站外的一个立交桥下,有两三个露宿者。

东京铁塔,吃了个可丽饼,感觉就是煎饼裹冰淇淋。

Day4: 小肥再进秋叶原
今天是去拿眼镜的日子。早上早起趁着人少先去了浅草寺。

之后步行前往东京博物馆,相较于国内博物馆主要以青铜器那种“实体用具”为主不同,东京博物馆的国内馆占比较多是字画等偏艺术等文物,也有一些甲胄、太刀之类的武器。发现了一个比较有趣的点:部分文物介绍中在中文和日文是有涉及中国的内容的,而在英文介绍中这一段话就消失了。

计划赶不上变化。原本是想着看完博物馆直接前往秋叶原的,结果忘了带提货单,只得从上野坐银座线回浅草。在回宾馆的路上看到一家くら寿司,不得不进去爽吃了。

拿上提货单后先去的秋叶原附近的神田神社购买KCA去东京必备物品——IT情报安全御守。

还得是能做出来这种御守的神社,太city了。在其他神社还只能用现金支付的时候,这家直接在神社里卖起来咖啡了。

拿了眼镜之后突然想起来还差一个点位没去,这就是

YuzuSoft!
在楼外面的标识实在太不清楚,在电梯上我都还一直在确认到底是不是这里,生怕不小心闯进了其他公司。整个屋子里除了店员剩下基本都在讲中文,一屋子全是老⏰是吧。
在animate发现50块钱一个的大吧唧,这大铁盘看着就爽。也是我为数不多地找到的邦老团的谷子。

晚上吃宇曼嘟嘟的鳗鱼饭,鱼肉中几乎没有刺,鱼肉外焦里嫩,咸郁的酱汁十分下饭。

Day5:镰仓之旅
没啥好说的,图片轰炸吧。










在江之岛的神社里看到一个倔强的柴犬。

晚上吃的一兰拉面,汤汁浓郁,好吃是好吃,就是太贵了。

Day6&Day7: 特种兵live之旅
day6上午去免税店采购伴手礼,在给妈妈买口红时被操着东北口音的中文店员的推销下额外买了900块钱的化妆品。😭
本来想着我就买个荧光棒,再怎么说荧光棒一人两个最基本的货应该得准备充足的把,下午两点开的场贩,我三点到场开始排队的,结果荧光棒sold out。于是紧急从现地群里找有没有群友有多带的荧光棒,最终在一个好心的群友手里收了两根蓝色高亮荧光棒。最终在live的时候担心影响到后面人,也只是在高潮的时候才打开亮光。

day1晚上是lisani day1,出场嘉宾有MyGo,之前一直不理解🐏噶,真线下见了能不成为🐏噶的也是神人了。LoveLive的星团,鲤鱼伟大无需多言。出场的还有一个四月即将放送的新番,是魔法少女类型的,下午场贩的时候也有这个动画的staff在场地里来回走动宣传初专。最后压场的是fripSide,还得是专业乐队,在唱功和调动氛围的能力上真不是盖的,气氛也在超跑OP里走向了高潮。

day2上午是烤的live,我预约的10点的现地受取,基本随到随取,完全无法理解那些排队排到场外的人。


演唱会是用的屏幕而非魔法未来那样的全息投影,不过效果意外地还不错。airi最高!烤的演唱会对比昨晚的来说,女性和小孩明显地多了,也有不少地雷女,符合我对日本原神的想象了。周边玩得也没昨晚的嗨,烤批还是太纯良了。
在演唱会安可期间恰好有群友出晚上的见切席,本来是没计划去看的,这下不得不去了。烤刚散场我就往门外跑,顺便从前排拾了两根彩带,坐1个小时的电车最终在开场前20min抵达武道馆。
lisani day2令我印象最深刻的是学偶的手毬,唱功在学偶企划里算是第一档的,会场里也有不少学P。我参加的这两场里,毛球是唯一一个被喊安可的。
散场后吃了今天第一顿正式的饭,食其家的寿喜烧。有些甜甜的,十分下饭。就是米饭配面条有点逆天。

吃完后回宾馆拿行李前往平和岛温泉,洗了个澡泡了几分钟温泉,在休息室里躺了几个小时便坐包车前往羽田机场准备回国了。东京到大阪的这一程依旧是摆渡车😅
当天天气很好,在飞机上看到了富士山。

后记
这是我第一次出国旅游,行前找了一大圈也没找到同行者。全程行程安排的很松,每天的实际游玩时间大概也就半天。不得不说日本人的素质是在线的,再小的街道也十分干净,有施工队在路边堆土也是在事先铺好的塑料布上。在镰仓马路边看到一家带院的一户建,围栏也就半人高,屋子通往外院的是一个没有任何防盗功能的玻璃门。电梯基本都是左立右行,不过不同电车站内有的靠左行有的靠右行这点令我十分困惑。服务业先不管他是不是装的,服务态度十分积极,不跟国内某些从业者一样仿佛顾客还欠他钱一样。宾馆每三天有次大扫除,甚至会把我乱丢的东西给归置整齐、衣物也给叠好,有点不好意思了//
第一次看演唱会,第一次跑现地,除了花销过多,总的来说是个十分有趣的旅程。
-

Docker跨平台导出/导入镜像时报错:”archive/tar: invalid tar header”
今天在把windows上使用
docker save [image] > file.tar导出的镜像导入至Linux平台时报错archive/tar: invalid tar header。在 Stack Overflow检索后发现是powershell的问题:I’ve found it’s not a windows specific issue. It’s a powershell issue. Powershell emits two byte characters to STDOUT, not one byte characters. If you look in the file you’ll notice that the TAR header has nulls between what should be the correct header (and in the rest of the file). This explains why the file is twice the size.
CMD on the other hand does not emit multibyte characters to STDOUT. I’ve found the STDOUT method of saving a file works fine across different OSes if you use CMD on windows.
——@GiskardReventlov
我发现这不是 Windows 特有的问题。这是一个 Powershell 问题。Powershell 会向 STDOUT 发送两个字节的字符,而不是一个字节的字符。如果你查看文件,就会发现 TAR 头本应是正确的头之间(以及文件的其他部分)有空格。这就解释了为什么文件的大小是原来的两倍。
另一方面,CMD 不会向 STDOUT 发送多字节字符。我发现,如果在 Windows 下使用 CMD,STDOUT 保存文件的方法在不同操作系统下都能正常工作。因此,在Windows打包Docker镜像时,最好使用
docker save [image] -o file.tar和docker load -i file.tar。 -
论文导图|CALF:通过跨模态微调对齐 LLMs 以进行时间序列预测
Peiyuan Liu1,∗ Hang Guo1,∗ Tao Dai2,B Naiqi Li1,B Jigang Bao1 Xudong Ren1 Yong Jiang1 Shu-tao Xia1
Tsinghua Shenzhen International Graduate School
2Shenzhen University
arXiv:2403.07300v2 [cs.LG] 23 May 2024
-
将大语言模型用于时序数据分析
1.LLM时序分析面临挑战
- 第一个挑战是知识可迁移性。时间序列数据具有季节性和趋势性,同时包含随机性或噪声。由于分布偏移,这些特征在不同领域或同一领域的不同时间可能差异显著,增加了模型或时间序列表示迁移的难度。
- 第二个挑战与数据稀疏性有关。传统时间序列数据集因按日、月或年收集而稀疏,且受隐私限制,如心电图分类数据获取困难。数据稀缺性限制了深度学习模型的有效训练,现有数据集往往不足以支持高质量模型学习。
- 第三个挑战与多模态学习有关。在多模态时间序列分析中,整合不同模态数据可提升模型性能和可解释性。例如,股票走势预测中整合社交媒体信息可提高预测精度。但将不同频率或间隔的多模态数据对齐以反映时间关系具有挑战性,且不同模态需不同技术捕获信息,整合这些信息至连贯模型复杂。
- 最后,可解释性也是高度需要的。模型生成预测或识别模式的详细解释能显著提升时间序列的效用和可接受性。例如,公用事业公司需向监管机构和消费者证明其能源需求预测模型的决策合理性。然而,现有时间序列模型多为黑盒,缺乏对模型行为或预测的解释。
2.时序数据
就通道数而言,时间序列数据可分为单变量时间序列和多变量时间序列。对于长度为 T 的单变量时间序列样本 $X = \lbrace x_t \rbrace_{t \in \lbrace 1, \dots, T\rbrace} \in \mathbb{R}$
,$x_t$是在时间戳 t 采集到的时间信号。对于具有N维的多变量时间序列样本$ X=\lbrace x_t \rbrace_{t\in {1,…T}} \in \mathbb{R}^{N\times T}$ ,每条记录$x_t$是特定时间戳 t 的信号。要处理多元时间序列的不同通道,有两种常用的策略[112]:通道混合和通道独立。在通道混合策略中,时间序列模型将首先把多个通道投射到隐空间中进行通道融合。在通道独立策略中,模型将单独处理不同的信道,这表明所有信道共享同一个模型。与投影器取决于多元时间序列通道数量的通道混合相比,通道独立配置可以轻松处理具有不同通道的时间序列。因此,信道无关性被广泛应用于带有域转移或模型预训练的时间序列分析。 一般来说,主流的时间序列分析任务包括时间序列分类、时间序列预测、时间序列估算和时间序列异常检测(如图所示)

TS(Time-series)数据具有以下属性:
- Temporal Dependency:按不同时间戳收集的时间序列数据本身就具有时间依赖性。过去的观测结果可作为预测未来值的指标。因此,时间序列分析模型通常需要将时间序列的子序列作为输入,以有效辨别这些潜在的时间关系。例如,在各种实际情况下,时间序列数据会表现出非平稳性和季节性等特征。 非平稳性指的是序列的统计属性,如其分布随时间而变化。这种可变性给预测带来了复杂性,因为在数据生成过程发生变化的情况下,过去的趋势可能不会持续下去.季节性是时间依赖性的另一个重要方面,它包括在固定时间间隔内(每天、每周、 每月或每年)发生的一致且可预测的波动。识别和理解季节性可以将这些周期性模式和一些时间戳信息纳入预测,从而改进对数据的理解和分析,从而增强建模过程。
- Spatial Dependency:对于多变量时间序列数据,单个时间序列可以代表复杂系统的不同实体。序列间的关系被称为空间依赖性,对于整体系统建模至关重要。 一方面,多元时间序列中的某些变量可能无法为模型构建提供充足的信息。另一方面,有效的空间依赖性建模对于揭示时间序列数据中隐藏的模式至关重要。
- Semantics Diversity:Unlike image and text data, where consistent semantics can often be found across different domains (with each word or visual patch representing similar meanings in various sentences or images), time series data lacks this uniformity. Identical subsequences or shapelets in time series datasets can represent entirely different concepts depending on the context. This variability complicates the process of learning representations and transferring models in time series analysis, presenting unique challenges to accurately interpret and utilize the data. (相同/相近的趋势在不同背景下反映的情况不一样)
3.预训练基础模型的关键阶段
基础模型(foundation model)是指在大规模、多样化数据集上训练后,通过微调适应多种下游任务的模型。这些模型源自深度学习,结合了自我监督学习和迁移学习,随着规模增大,展现出强大的零次/少次学习及链式思考推理能力,尤其在NLP和CV领域表现突出。与LLM专精与NLP不同,基础模型在多领域均有应用。
传统时间序列分析因数据不足,难以训练复杂模型,因此社区期待基础模型能在有限数据上展现优异性能。尽管NLP和CV领域的基础模型发展迅速,但基于时间序列的基础模型较少,主要因数据集规模小。不过,已有如ForecastPFN、TimeGPT等模型出现,表1提供了这些模型的比较。
Model Parameter Size Transformer Mode Channel Setting Task Type Pre-trained Dataset Data Size ForecastPFN – Encoder-only Uni. Fore. Synthetic Data – TimeGPT – Encoder-decoder Uni. Fore. – 100 B time points TimesFM 225M Decoder-only Uni. Fore. Google Trends, Wiki Pageviews, Synthetic Data 101 B time points Lag-Llama – Decoder-only Uni. Fore. Monash 0.3 B time points TimeCLR – Encoder-only Uni. Class. UCR – GTT 57M Encoder-only Multi. Fore. – 2.4 B time points 3.1 数据处理
3.1.1 数据收集
大语言模型(LLMs)的泛化能力得益于大规模、高质量的文本预训练。同样,时间序列分析中,广泛且高质量的数据对构建有效基础模型至关重要。
- 数据拆分:在构建遵循标准协议的基础模型时,预训练数据集被分为训练集和验证集。在微调阶段,模型会接触到在预训练阶段未见过的目标数据集,每个数据集进一步被拆分为训练集、验证集和测试集。
-
数据源和规模:在现有的时间序列预测基础模型中,Lag-Llama在Monash时间序列仓库上预训练,GTT收集了180,000个时间序列,TimesFM选择Google趋势等数据源,TimeGPT构建了超过1000亿数据点的仓库,但未公开。
-
数据增强:为了扩大预训练数据集,现有工作采用了各种数据增强技术。Lag-Llama 使用 Freq-Mix 和 Freq-Mask 来生成更多的训练样本以防止过拟合。TimeCLR 采用了数据增强技术(例如抖动、时间扭曲、裁剪)来生成更多数据,使模型对扭曲、不同的噪声类型等具有不变性。ForecastPFN 不是在真实世界的数据上进行预训练,而是在完全合成的数据分布上进行预训练。
-
数据质量:数据质量对于确保模型的有效性至关重要。时间序列数据中常见的挑战包括缺失值、噪声和异常值。为了消除可能导致梯度爆炸的多样异常值,ForecastPFN 首先掩盖缺失值,然后裁剪所有 3σ 异常值。类似地,GTT 通过消除归一化值超过 9 的数据点来消除极端异常值。
3σ准则 3σ准则又称为拉依达准则。 所谓3σ,当数据被定义为在一组测定值中与平均值的σ(标准偏差)超过3倍时,这个值就被认为是异常值,而这个异常值的概率通常小于0.3%,用公式可以理解为p(|x−μ|>3σ)⩽0.003 。
3.1.2 数据对齐
在时序分析中,数据对齐(Data Alignment)是一个关键步骤,尤其是在多变量、多源数据的情况下。数据对齐是指在处理多个时间序列时,将不同来源的数据点依据时间维度进行同步,以便后续的分析、建模和预测工作能够准确地反映各变量之间的相互关系。基础模型在多个异构数据集上预训练,需对齐和平衡以增强泛化能力。时间序列数据的处理面临值范围可变性的挑战,传统的缩放方法不适用。数据对齐的过程通常包括以下几个重要方面:
- 时间戳同步
多个时间序列可能来自不同的数据源或以不同的时间戳记录。因此,第一步是确保所有的时间序列都有一致的时间戳格式,并在统一的时间尺度上进行同步。常见的方法包括:
- 时间戳格式标准化:将所有时间戳转换为相同的格式(如UTC)或单位(秒、分钟、小时等)。
- 对齐采样频率:不同数据源可能有不同的采样频率(如每秒、每分钟、每小时),因此需要调整时间序列的采样频率使其一致。这可以通过插值、降采样或重采样来实现。
- 插值与缺失值填充
在对齐过程中,常常会遇到缺失的数据点,尤其是当两个或多个时间序列的记录频率不同步时。常见的处理方法包括:
- 线性插值:通过两点之间的线性关系来估计缺失的数据点。
- 前向填充和后向填充:用之前或之后的可用值填充缺失值。
- 样条插值:利用多项式或样条函数进行插值,适用于非线性数据。
- 移动平均:通过取前后数据点的均值来填补缺失值,平滑时间序列。
- 时间窗口对齐
有些时间序列的数据可能并非连续记录,而是基于某个特定时间窗口(例如每天、每小时)生成的。这种情况下,数据对齐需要确保每个时间窗口内的数据点能够在不同的序列之间匹配。时间窗口对齐的一些常见方法包括:
- 固定窗口对齐:将所有时间序列数据切分为固定的时间窗口(如1分钟、1小时),并确保每个时间窗口内有可比数据点。
- 滑动窗口对齐:使用滑动窗口的方法,使得窗口的大小固定但窗口的起点是逐步滑动的,适合需要捕捉序列中动态变化模式的场景。
- 可变上下文长度(TimesFM):可变上下文长度指的是模型可以根据数据的特点和变化动态调整处理的时间窗口大小,而不是使用固定的窗口长度。在传统的时序模型中,窗口长度通常是固定的,如滑动窗口、移动平均等。而在 TimesFM 中,上下文窗口的长度可以根据时间序列的特定模式动态变化,这使得模型能够更好地处理数据中的短期波动和长期趋势。
- 数据变化速度:当数据变化较快时(例如金融市场的波动),模型会缩短上下文长度,以便快速捕捉变化。
- 噪声水平:当数据中噪声较多时,TimesFM 会使用较小的窗口进行局部平滑处理;当数据质量较高时,模型会使用较大的窗口平滑整体趋势。
- 卷积平滑:CNN 可以用于捕捉局部模式,通过卷积核大小的变化,实现不同尺度的平滑处理。
- 记忆机制:LSTM 或 Transformer 允许模型记住长时间的历史信息,使其能够根据较长的历史数据进行更复杂的平滑处理。
- 时间滞后(Lag)处理
在某些情况下,不同时间序列之间可能存在因果关系或时间滞后效应。例如,一个序列的变化可能导致另一个序列在数小时或数天后发生变化。这时,可以通过引入滞后项来对齐这些时间序列,以捕捉滞后效应。常见的做法是手动或通过建模寻找最优滞后时间,并将其应用于数据对齐。
- 降采样与升采样
- 降采样(Downsampling):如果一个序列的数据频率较高,可以通过计算平均值、最大值、最小值等方式将其降采样至与其他序列相同的频率。
- 升采样(Upsampling):当一个序列的数据频率较低时,可以通过插值或数据合成的方式升采样,以便与其他高频数据源对齐。
- 数据变换与标准化
有时,在对齐之前,可能需要对不同的时间序列进行标准化或归一化,使它们在相同的尺度上进行对比。这包括:
- 归一化:将数据缩放到[0,1]的范围内,确保不同量纲的数据可以对齐。
- 标准化:将数据转化为均值为0,方差为1的标准正态分布,便于序列的比较。
GTT和Lag-Llama采用特定样本归一化技术提升模型便利性。GTT通过固定通道数和上下文长度处理多通道数据,而TimesFM使用可变上下文长度实现数据平衡。模型对齐的关键措施包括值缩放、处理输入输出长度变化、管理多通道数据和实施平衡采样,这些对稳定训练和防止性能下降至关重要。
3.2 架构设计
3.2.1 Backbone for Foundation Model.
A deep learning model can serve as the basis for a foundation model, provided that its size can be scaled up. Scaling is indeed crucial for developing remarkably successful LLMs Due to transformer architecture’s outstanding capacity for parallelization, it allows scaling to a massive number of parameters, making it the preferred backbone for LLMs.
In the context of time series analysis, TimeCLR compares several backbone models, including GRU, LSTM, ResNet, and transformer, and finds that the transformer outperforms the alternatives. Ultimately, all the existing foundation models choose transformers as their backbone models. The key differences among these transformer-based foundation models lie in the transformer mode, input tokenization, and predictive objects. We will continue the discussion and comparisons in the following. Note that additional potential architectures have been suggested in, including Transformer++ and State-Space Models.
3.2.2 Transformer Mode.
Transformer 模型包括编码器和解码器,有三种模式:仅编码器(如BERT)、仅解码器(如GPT系列)和编码器-解码器(如BART和T5)。仅解码器模型在零样本和少样本学习中表现出色,GPT-3是典型例子。仅编码器模型适合处理整个输入序列的任务,如分类和情感分析,而解码器模型适用于顺序生成任务,如文本生成。编码器-解码器模型因其输入输出分离在复杂任务中占优。GTT和ForecastPFN为时间序列预测开发了仅编码器模型,而TimesFM和Lag-Llama选择解码器模式。TimeGPT采用编码器-解码器模式以处理复杂数据。
3.2.3 Channel Setting.
Another issue relevant to the architecture design of time series foundation models is the channel setting, specifically channel-independence and channel-mixing. Channel-independence refers to accept univariate sequence input while channel-mixing involves the utilization of multivariate sequence input. These different channel settings result in varied tokenization approaches for time sequences and necessitate distinct model designs.
通道独立:单变量模型设计相对简单,因为多变量数据的通道数可能变化。多数研究倾向于使用通道独立,通过不同的技术如PatchTST、TimesFM、Lag-Llama和TimeCLR将单变量序列转换为向量序列。
通道混合:将多变量序列分解为多个单变量序列可能会忽略不同通道/变量之间的关系和相互作用。GTT为时间序列预测建立了一个多变量基础模型。他们将渠道变量重塑为批量大小,从而得到单变量序列,并将其切成片段。在推理阶段,由于通道变量已与批量大小融合,因此模型可以接受不同的通道数。
4 使LLM处理时序数据的方法
有两种时间序列的LLM适应范式:(a)嵌入可见大语言模型,通过重新设计LLM直接感知时间序列嵌入来适应时间序列任务。(b)文本可见大语言模型,通过以句子对句子的方式制定时间序列的输入-输出来适应时间序列任务。
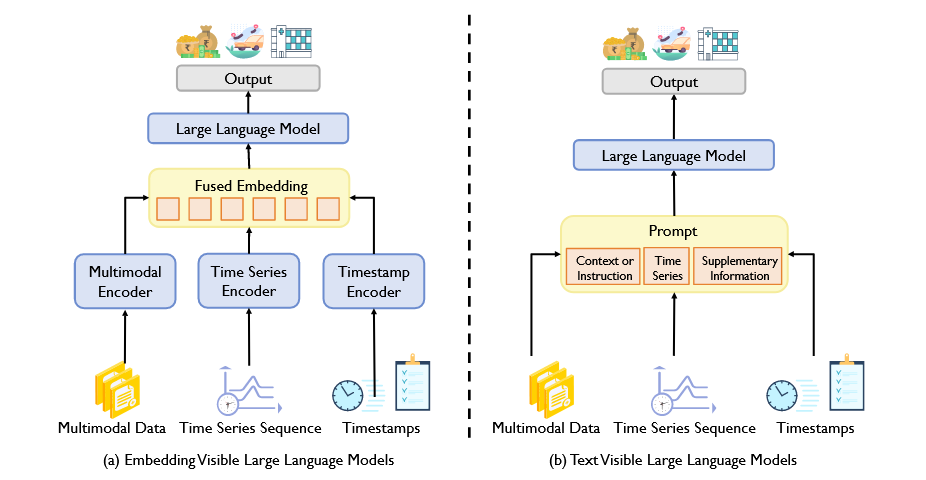
这两种范式在输入-输出方式、LLM利用和数据融合上有所不同。LLM不仅用于预测,还可作为增强器、数据生成器和解释器,扩展了其在多种应用中的功能。本节将介绍关键概念,分析各范式的关键阶段,并探讨LLM在时间序列问题中的多重角色。
01、嵌入可见的LLM调整
嵌入可见的LLM调整利用传统的 “预训练和微调” 范式重新设计LLM,并将其微调用于下游时间序列任务。在这个范式下,LLM被重新设计为直接感知时间序列嵌入,而不是传统的文本输入。
(1)向量化的时间序列表示
在时间序列分析中应用LLM时,首先需将时间序列数据转换为LLM可处理的向量序列。在嵌入可见的LLM调整中,时间序列被向量化,LLM被重新设计以直接感知这些时间序列嵌入。受Transformer模型分块策略的启发,研究者将时间序列切分为固定长度的块,作为LLM的输入标记,以保留局部语义信息。对于多变量时间序列,常分解为单变量序列后进行分块处理。然而,TEST模型在通道混合设置下处理时间序列,强调不应忽视跨变量的依赖关系。
(2)时间序列和LLM之间的语义空间对齐
时间序列转换为向量序列后,需解决与LLM认知嵌入空间的模态差距。研究者通过重新设计输入嵌入层并在特定数据集上微调LLM,以对齐时间序列与LLM的维度空间。Time-LLM和TEST等研究使用文本原型重新编程嵌入,通过对比学习和多头注意力层,使时间序列特征与语言元素对齐,以增强LLM对时间序列的理解。
(3)时间序列的特性和模式识别
时间序列与自然语言在模式和属性上有本质差异,这给LLM应用于时间序列任务带来挑战。时间序列的独特特征包括多变量依赖、分布偏移和复杂时间模式。尽管基于Transformer的模型在某些任务中表现出色,但它们可能忽视时间序列的独特属性,如趋势和季节性。研究表明,时间序列Transformer在鲁棒性上可能不如其他模型,且LLM在预训练阶段缺乏识别时间序列特性的能力。因此,在应用LLM于时间序列分析时,考虑这些特性至关重要。
- 时间模式:TEMPO方法将单变量序列分解为趋势、季节和残差,简化了LLM的预测,并通过可学习的提示池编码共享时间模式。分解后的部分经过归一化、补丁化和嵌入,与提示一起输入GPT模块。实验验证了分解和提示池的有效性。AuxMobLCast在编码器-解码器架构中加入辅助POI分类模块,以识别与不同POI类别相关的访问模式,消融研究显示此模块显著提升了BERT编码器的性能。
- 多变量依赖性:时间序列数据常为多变量,如股票价格和ECG数据,而文本是单变量的。许多研究将LLM调整为处理多变量时间序列,但TEST指出通道独立性方法忽略了多变量依赖性。TEST直接处理多变量时间序列,将其切片成不同长度的标记,输入编码器生成时间嵌入,以捕捉变量间的相互依赖。
- 时间戳信息:研究表明,在基于Transformer的模型中加入时间戳信息,如在疾病预测和交通流量预测中,能提升模型性能。LLM4TS为每个时间序列补丁分配初始时间戳,编码时间属性并融合成时间嵌入,与标记和位置嵌入结合生成最终嵌入。
- 分布偏移:FPT和TEMPO采用反向实例归一化(RevIN)对单变量输入序列进行归一化,以减轻分布偏移并促进知识传递。然而,LLM4TS指出RevIN的可训练仿射变换不适用于自回归模型如GPT-2,因此在监督微调阶段使用标准实例归一化。
(4)多模态数据融合
多模态学习在NLP和CV领域广泛研究,如视觉问答和图像-文本生成。时间序列分析中也存在多模态场景,如金融和医疗数据集可能包含文本或图像信息。时间序列数据的抽象性使得语义挖掘和知识传递具有挑战性,但通过多模态信息补充可以增强模型对复杂时间模式的学习,提升表示能力、泛化能力和可解释性。受多模态LLM成功的启发,研究者设计了用于时间序列分析的多模态模型,根据信号粒度分为两类。
(5)样本级多模态融合
研究者利用多模态信号如文本报告来丰富时间序列样本的细节,增强内部知识。METS结合ECG信号与临床报告,使用ClinicalBert模型提取诊断知识,指导ECG编码器训练。TEMPO则结合季度新闻和报告,预测财务指标,并利用时间嵌入和软提示提取摘要信息。这些方法通过多模态信息提升时间序列分析的深度和准确性。
(6)任务级多模态融合
另一研究方向利用多模态知识提升模型泛化能力和跨数据集知识传递,涉及任务或领域级别。UniTime通过领域指令帮助模型识别数据源并调整预测策略,指令以句子形式包含领域知识,与时间嵌入融合。Time-LLM采用Prompt-as-Prefix技术,使用包含领域知识、任务指令和数据统计的提示增强时间序列表示,促进LLM的推理和模式识别。
(7)微调
微调预训练的LLM对于其在特定任务中的应用至关重要,涉及重新配置输入/输出层和目标函数。UniTime通过完全微调GPT-2在跨领域时间序列预测中取得最佳性能,但全参数更新可能导致灾难性遗忘和资源需求增加。为解决这些问题,研究如FPT、TEMPO和LLM4TS采用部分参数更新,而TEST和TimeLLM则使用冻结LLM结合可学习软提示。这些方法旨在减少参数更新,同时保持性能,并需对齐时间序列嵌入与LLM文本空间。此外,通过识别时间模式和整合多模态信息,进一步增强LLM在时间序列分析中的能力。
02、文本可见的LLM调整
文本可见LLM调整遵循 “预训练、提示和预测” 的范式,重新设计时间序列任务,并利用提示技术激活LLM的能力。在这个范式下,时间序列任务的输入-输出对被重新构造为文本提示。
(1)文本化的时间序列表示
在文本可见的LLM调整中,时间序列数据被转换为字符串,以便与提示无缝集成。研究者使用LLM直接推断任务,无需微调,通过句子对句子格式化任务。数值数据被描述为自然语言句子,并结合上下文信息。对于特定任务,如人类移动性预测、健康任务和天气预测,LLM被微调,并以自然语言形式制定任务。
(2)时间序列和LLM之间的语义空间对齐
在将时间序列转化为句子的工作中,LLM通过标记化理解字符串,但原始标记化方法可能不适用于数值,导致连续数值被分割并忽略时间意义,增加算术运算复杂性。LLMTIME建议在标记化前对时间序列进行预处理,如为GPT增加空间技术。提示调整作为一种潜在解决方案,通过添加可训练嵌入优化输入,帮助LLM理解时间序列信息。
(3)时间序列属性和模式识别
与嵌入可见LLM调整下的时间序列特征提取不同,文本可见LLM通过将相关信息集成到提示中来识别时间序列的独特属性和模式。
- 时间模式。 LLM-Mob指出LLM难以直接从复杂停留数据中提取有用信息进行人类移动性预测,因此提出分解数据为历史和上下文序列,以帮助LLM理解长期和短期移动模式。AuxMobLCast发现POI类别与乘客模式相关,通过集成辅助POI分类模块到编码器-解码器架构中,显著提升了BERT编码器的性能。
- 跨序列依赖。为了解决股票预测中的跨序列依赖问题,TDML从相似股票中提供大量示例,以创建上下文学习提示,证明LLM能有效整合跨序列信息。LLMST将所有轨迹整合在一个提示中,以观察模型是否能考虑轨迹间交互,发现这可能提升性能。TWSN利用多个历史股票特征,将多元价格特征转化为表格格式的字符串,并整合到文本提示中,用于股票走势预测。
- 时间戳信息。 UMEF将时间戳信息整合到能源消耗预测模板中。LLM-Mob在人类移动性预测中考虑目标停留时间的时间信息,并通过融入与时间和日期相关的事实引导LLM分析移动模式的变化。AuxMobLCast在移动性提示中包含日期信息,发现删除时间日期信息后性能下降,表明时间戳有助于LLM捕捉时间模式。
(4)多模态数据融合
文本可见的LLM设置中对多模态学习的研究较少。TWSN在样本级多模态数据融合中,结合历史股票价格和推文构建多模态提示,评估ChatGPT在股票走势预测中的能力。任务级多模态数据融合中,任务级信息作为补充添加到提示中,以提升模型性能。
(5)提示
受LLM在NLP中泛化能力的启发,研究者使用提示激活LLM在时间序列任务中的能力,将输入整合到文本提示中,引导LLM生成期望的自然语言输出。提示分为无调参和基于微调两种,前者在零样本/少样本设置下评估性能,无需微调,后者则微调LLM并更新参数。综述中总结了两种方法并讨论了它们的优缺点。
- 无调参提示:研究者通过设计指令提示,利用LLM的内部知识进行零样本/少样本推理,无需参数更新。TDML优化提示结构,发现零样本CoT提示能显著提升性能。TWSN评估ChatGPT在股票预测中的表现,发现CoT技术虽有提升但不及专门方法。LLMF测试PaLM-24B在健康问题上的零样本性能,发现其在数值任务上表现不佳。LLMST和LLM-Mob通过设计提示评估LLM在移动性异常检测中的性能,强调提示工程的重要性。LLMFS发现PaLM在少样本学习中能处理健康数据,但在零样本设置中性能下降。LLMTIME则表明,通过仔细预处理时间序列,LLM可直接作为零样本预测器,无需额外文本信息。
- 基于微调的提示:为了克服仅利用LLM固有知识的局限性,一些研究结合了传统微调和提示,更新LLM参数以适应特定时间序列任务。PromptCast采用指令微调进行通用时间序列预测,设计了零样本基于指令的提示,用于天气、能源和客流量预测。UMEF在能源消耗预测中使用无指令微调,将数据转换为描述性句子。AuxMobLCast利用无指令微调进行人类移动预测,结合移动数据、时间戳和POI信息,微调编码器-解码器架构。LLMFS为健康任务设计了基于问题-回答的提示,冻结LLM并添加可学习提示嵌入,以理解不同任务的时间序列数据。这些方法通过微调和提示结合,提升了LLM在时间序列任务中的性能。
总之,利用提示的研究的关键贡献在于它们针对特定的时间序列场景设计了复杂的提示。为了增强提示的有效性,一些研究还整合了额外的信息,如时间序列特征、替代数据模态和专家知识。像思维链(CoT)这样的技术已经应用于几项工作中,显示出提高模型性能的潜力
5 LLM的可解释性
可解释性是指人类对模型的行为或预测的理解程度,这一直是人工智能和时间序列领域的重要问题。让模型变得透明和可解释,可以让用户理解、适当信任和有效管理在真实世界场景中部署的模。在某些情况下,合格的模型性能虽可以满足大多数要求,但对于那些用户信任、安全、公平和隐私至关重要的关键决策领域,如自动驾驶、医疗保健和金融,缺乏可解释性将阻碍模型的实际应用。解释性的好处远不止于知识发现、模型调试以及解决人工智能系统与人类专家之间的分歧。
虽然某些模型(如决策树)因其简单明了的结构本质上具有可解释性,但大多数模型,尤其是深度学习模型,本质上都是黑箱,其内部工作机制对用户来说是模糊的。为了应对这一挑战,可解释人工智能(XAI)领域致力于开发能让人类理解深度学习模型内部机制或结果的方法。XAI 研究大致可分为两种方法:局部解释和全局解释 。局部解释旨在阐明模型对特定实例做出决定的原因,力求揭示给定输入与其结果之间的因果关系。与此相反,全局解释则致力于揭示模型的整体内部机制,检查所有实例的结构和参数。解释技术还可分为事前方法和事后方法。前置方法直接结合模型结构的可解释性,而后置方法则侧重于在不改变模型底层结构的情况下解释模型行为。
-

工业5.0:以人为本的新生产范式
序
工业 4.0,又称第四次工业革命,已经对全球经济和各行各业企业的运营方式产生了巨大影响。该技术帮助企业变得更加敏捷、高效,甚至更加环保。工业 4.0 的最大特点之一是使用互联技术,使企业能够交换实时数据、优化流程、降低成本并提高质量。
而工业5.0是正在兴起的下一个工业革命阶段,强调以人为本,使人们能够更好地利用自身技能,创造一个工作更安全、高效且富有意义的未来。工业5.0将继续引入诸如人工智能(AI)、机器人技术等尖端科技,但重点是人机协作,使技术与人类的独特能力相互补充。对于企业来说,工业5.0带来了前景广阔的未来,值得关注其发展动向。
什么是工业5.0

第一次工业革命的标志是蒸汽机的发明,开启了工厂作为新生产组织形式的时代;第二次工业革命则由内燃机的使用和电力的广泛应用所驱动;第三次工业革命则是在信息技术、计算机自动化和核能技术推动下兴起。
工业4.0,或称第四次工业革命,是以虚拟和实体相结合为代表的新一次产业革命。伴随着物联网的广泛应用、存储空间和算力的不断提升,大数据和人工智能技术的迅速发展,信息物理系统(或智能计算机)正在塑造第四次工业革命。借由数字孪生,在虚拟空间创造一个物理世界的数位副本,通过边缘节点实时收集数据,人工智能通过实时分析海量数据监控生产情况、预测设备故障并给出解决方案。通过自动化和技术提高制造和生产效率,使用数据和分析来优化流程, 物联网、人工智能、机器学习用于任务和决策自动化, 用于重复性、危险性或精密性任务的机器人和自动机器, 智能工厂可自我优化生产流程,预测性维护、远程监控和实时数据分析,以提高效率并降低成本,是工业4.0下智能工厂的目标和愿景。
但很多人对工业4.0中“机器会不会取代人”这一问题表达了担忧。2021年4月,欧盟公布了《工业5.0:迈向可持续、以人为本和富有弹性的欧洲工业》(Industry5.0: Towards a Sustainable, Human-centric and Resilient European Industry)报告,以此确定了其“工业5.0”的基本理念,即以人为中心(Humancentric)、可持续(Sustainability)和韧性(Resilience)。工业5.0是对现有“工业 4.0”方法的补充而不是替代,在工业5.0中,强调了生产的环境友好和可持续,注重人在生产中始终处于核心地位、确保人的福祉。

以人为本
工业5.0的核心理念之一是人机协作。与工业4.0注重自动化不同,工业5.0认为人类的创造力、灵活性和决策能力是不可替代的,技术的进步应该与人类的潜能结合。通过让技术支持人类而非取代人类,工业5.0促进了工作环境的转变,使员工能在自动化和机器人技术的辅助下完成更有意义的工作任务。
可持续性
工业5.0强调建设一个现代化、资源高效、可持续的产业以及向循环经济转型。。它不仅意味着在生产过程中更加注重环境保护,减少碳排放,还鼓励企业持续为员工提供技能培训,使工人在这个快速发展的科技时代保持竞争力。这种以环境和人类福祉为中心的可持续性将成为未来工业发展的主旋律。
韧性
企业要迅速适应市场变化,及时调整生产,以保持领先地位。即使在发生自然灾害或其他危机时,也能继续保持高水平的运营。它与可持续发展相辅相成,有助于公司与自己的目标和目的保持一致。企业战略的首要关注点将不再是增长、利润和效率,而是打造“不脆弱”的组织,即能够及时、系统地预测、应对和学习任何危机,从而确保稳定和可持续的绩效。
工业5.0是对工业4.0的有力补充,它不仅推动了技术的进一步发展,还将人类置于生产过程的中心。通过引入更高效、灵活的技术手段,工业5.0有助于企业实现更可持续的生产,同时确保员工的技能和创造力能够得到充分发挥。这一新的工业范式不仅关注企业的经济效益,更关注社会福祉和环境可持续性,未来发展前景令人期待。
-

WSL2+CUDA+PyCharm搭建PyTorch环境
序
国庆闲来无事,决定自己实际操作一下。首先要完成的任务就是环境搭建。本教程是Nvdia独显+Windows电脑+WSL2环境下的PyTorch安装以及使用PyCharm连接环境
安装
安装Miniconda
最简单的方法就是安装依赖Python 3.x的Miniconda。 如果已安装conda,则可以跳过以下步骤。访问Miniconda网站,根据Python3.x版本确定适合的版本。
对于64位元的Linux作业系统,可以使用以下官方提供的指令:
mkdir -p ~/miniconda3 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3 rm ~/miniconda3/miniconda.sh初始化环境
~/miniconda3/bin/conda init初始化完成后,提示关闭当前终端,重新打开新的终端
创建一个新的环境,其名称可以修改:
conda create --name d2l python=3.9 -y切换到d2l环境
conda activate d2l注意每次运行都要运行此指令。例如每次
source .bashrc之后。如要退出当前环境:
conda deactivate。
如要完整删除名为dal的环境:conda remove -n d2l --all安装CUDA
CUDA(官网)是英伟达官方的深度学习工具包,如图是WSL的选项。运行下载代码。
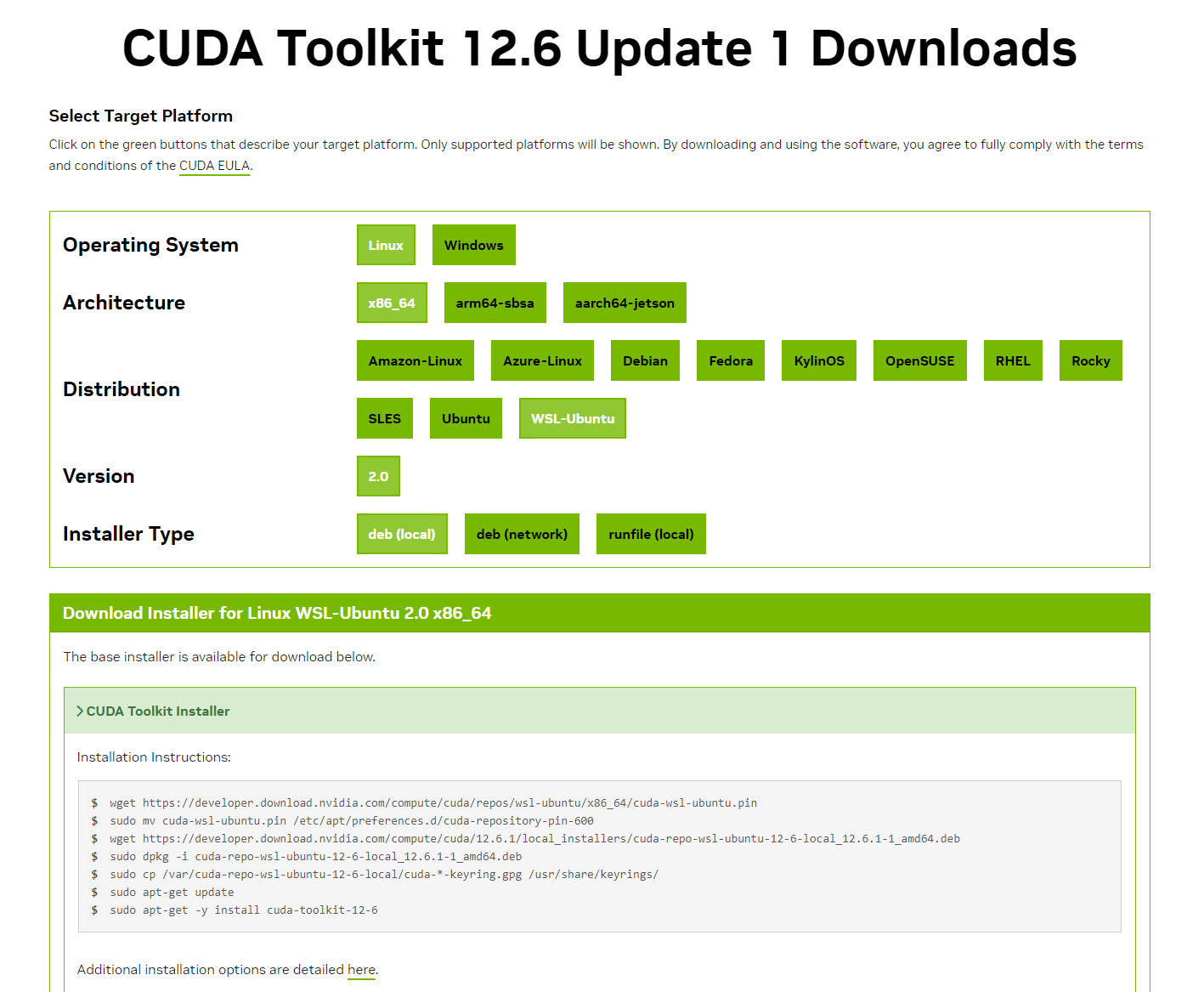
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600 wget https://developer.download.nvidia.com/compute/cuda/12.6.1/local_installers/cuda-repo-wsl-ubuntu-12-6-local_12.6.1-1_amd64.deb sudo dpkg -i cuda-repo-wsl-ubuntu-12-6-local_12.6.1-1_amd64.deb sudo cp /var/cuda-repo-wsl-ubuntu-12-6-local/cuda-*-keyring.gpg /usr/share/keyrings/ sudo apt-get update sudo apt-get -y install cuda-toolkit-12-6从官网安装的CUDA貌似需要手动设置环境变量
sudo vi ~/.bashrc conda activate d2li进入insert模式,添加以下代码到文件最后,注意修改为对应版本,此处使用cuda12.1。export PATH=/usr/local/cuda-12.1/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64\${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}Esc,:wq,回车保存。source ~/.bashrc conda activate d2l测试
在终端中执行
nvcc -V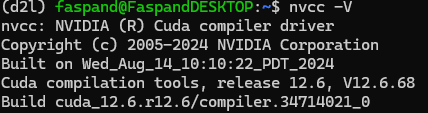
执行
nvidia-smi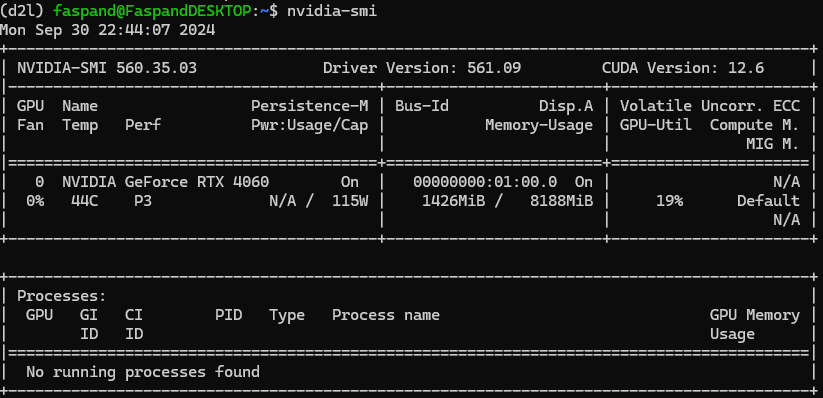
安装PyTorch
在PyTorch官网选择合适版本,CUDA版本可向下兼容。

确保指令在d2l环境下运行.
PyCharm连接WSL
新建一个Interpreter On WSL
等待检查完成
选择之前步骤中创建的d2l环境
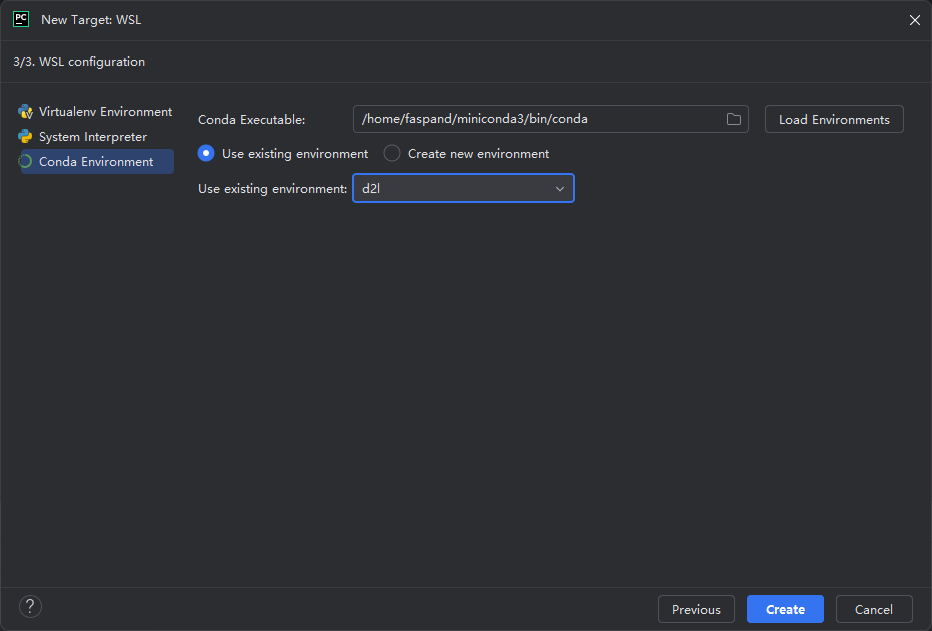
在python终端中测试可用性
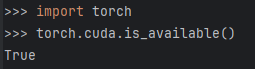
本文在写作过程中参考了以下资料
https://zh.d2l.ai/chapter_installation/index.html
https://blog.yotroy.cool/?p=274
https://www.jetbrains.com/help/pycharm/using-wsl-as-a-remote-interpreter.html#wsl-terminal
-

知识图谱与跨模态
知识图谱( Knowledge Graph)的概念由谷歌2012年正式提出,旨在实现更智能的搜索引擎,并且于2013年以后开始在学术界和业界普及。目前,随着智能信息服务应用的不断发展,知识图谱已被广泛应用于智能搜索、智能问答、个性化推荐、情报分析、反欺诈等领域。另外,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并且形成一套Web语义知识库。知识图谱以其强大的语义处理能力与开放互联能力,可为万维网上的知识互联奠定扎实的基础,使Web 3.0提出的“知识之网”愿景成为了可能。
1.定义
知识图谱:是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系。
知识图谱通过对错综复杂的文档的数据进行有效的加工、处理、整合,转化为简单、清晰的“实体,关系,实体”的三元组,最后聚合大量知识,从而实现知识的快速响应和推理。
知识图谱有自顶向下和自底向上两种构建方式。所谓自顶向下构建是借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库中;所谓自底向上构建,则是借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的新模式,经人工审核之后,加入到知识库中。
下图为一个简单的知识图谱:
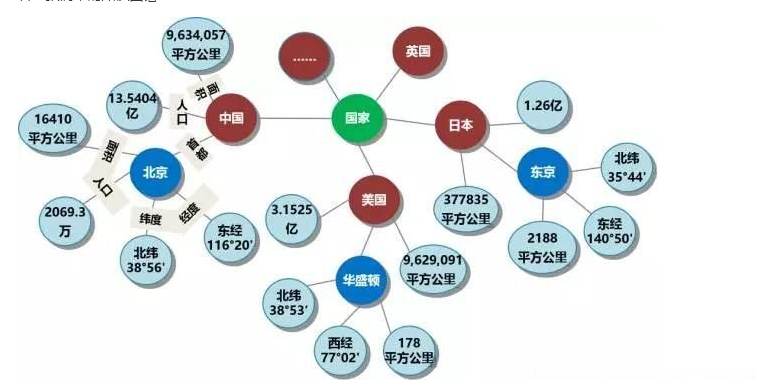
如图所示,如果两个节点之间存在关系,他们就会被一条无向边连接在一起,那么这个节点,我们就称为实体(Entity),它们之间的这条边,我们就称为关系(Relationship)。
知识图谱的基本单位,便是“实体(Entity)-关系(Relationship)-实体(Entity)”构成的三元组,这也是知识图谱的核心。
- 实体: 指的是具有可区别性且独立存在的某种事物。实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。如图中的“中国”、“北京”、“16410平方公里”等。
- 关系: 关系是连接不同的实体,指代实体之间的联系。通过关系节点把知识图谱中的节点连接起来,形成一张大图。如图中的“人口”、“首都”、“面积”等
2. 数据类型和存储方式
知识图谱的原始数据类型一般来说有三类(也是互联网上的三类原始数据):
- 结构化数据(Structed Data):如关系数据库
- 半结构化数据(Semi-Structed Data):如XML、JSON、百科
- 非结构化数据(UnStructed Data):如图片、音频、视频、文本
KG的存储方式通常有二,一个是通过RDF(资源描述框架)这样的规范存储格式来进行存储,还有一种方法,就是使用图数据库来进行存储,常用的有Neo4j等。
在知识图谱方面,图数据库比关系数据库灵活的多。
在数据少的时候,关系数据库也没有问题,效率也不低。但是随着知识图谱变的复杂,图数据库的优势会明显增加。当涉及到2,3度的关联查询,基于图数据库的效率会比关系数据库的效率高出几千倍甚至几百万倍。3. 知识图谱的架构
知识图谱在架构上分,可以分为逻辑架构和技术架构。
3.1 逻辑架构
知识图谱在逻辑上可分为模式层与数据层两个层次。
- 模式层构建在数据层之上,是知识图谱的核心,通常采用本体库来管理知识图谱的模式层。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
模式层:实体-关系-实体,实体-属性-性值
- 数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源的Neo4j、Twitter的FlockDB、sones的GraphDB等。
数据层:比尔盖茨-妻子-梅琳达·盖茨,比尔盖茨-总裁-微软
3.2 技术架构
知识图谱的整体架构如下图所示,其中虚线框内的部分为知识图谱的构建过程,同时也是知识图谱更新的过程。
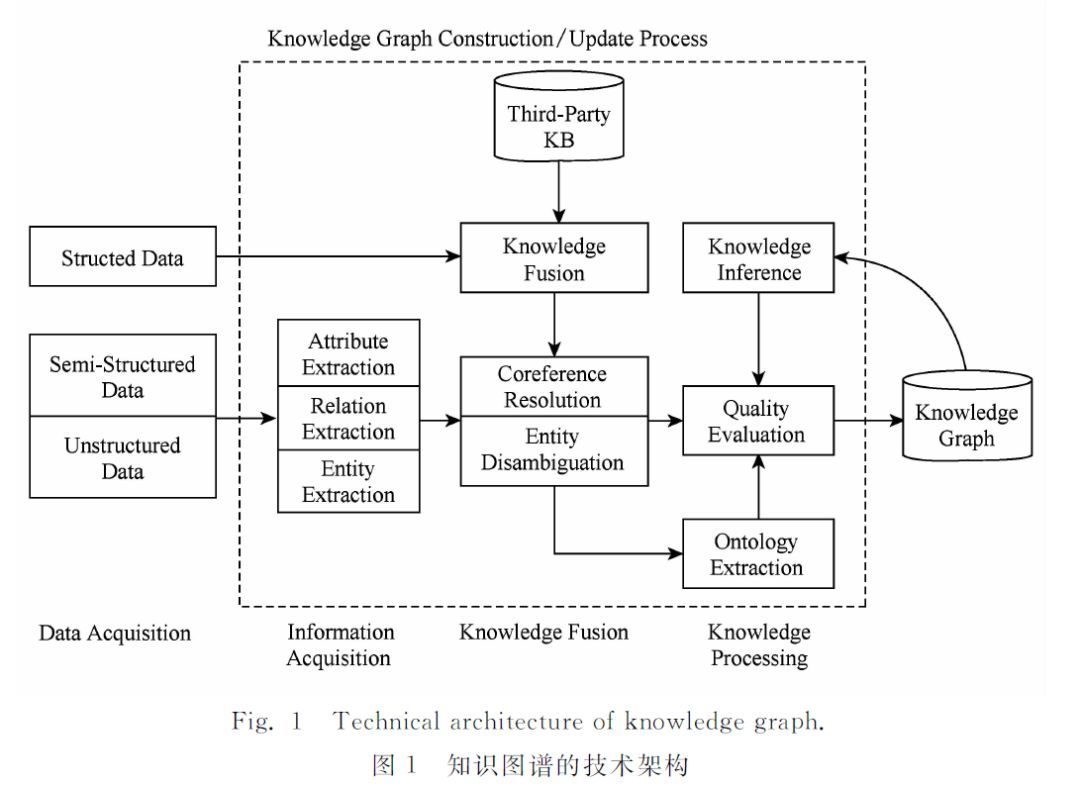
我们来一步一步的分析下这张图。
- 虚线框的最左边是三种输入数据结构,结构化数据、半结构化数据、非结构化数据。这些数据可以来自任何地方,只要它对要构建的这个知识图谱有帮助。
- 虚线框里面的是整个的知识图谱的构建过程。其中主要包含了3个阶段,信息抽取、知识融合、知识加工。
- 最右边是生成的知识图谱,而且这个技术架构是循环往复,迭代更新的过程。知识图谱不是一次性生成,是慢慢积累的过程。
- 信息抽取(information extraction):从各种类型的数据源中提取出实体(entities)、属性(attributes)以及实体间的相互关系(relationships),在此基础上形成本体化的知识表达;
- 知识融合:在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等;
- 知识加工:对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量。
其实我们的构建知识图谱的过程,就是信息抽取、知识融合、知识加工三个过程,但是这三个过程都有各自的难点,下文通过从这三个模块出发,解析这三个模块说要解决的问题,会遇到的难点。
4.信息抽取
信息抽取是知识图谱构建的第一步,其中的关键问题是:如何从异构数据源中自动抽取信息得到候选指示单元?
信息抽取是一种自动化地从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息的技术。
涉及的关键技术包括:实体抽取、关系抽取和属性抽取。
4.1 实体抽取(Entity Extraction)
实体抽取又称为命名实体识别(named entity recognition,NER),是指从文本数据集中自动识别出命名实体。实体抽取的质量(准确率和召回率)对后续的知识获取效率和质量影响极大,因此是信息抽取中最为基础和关键的部分。

2012年Ling等人归纳出112种实体类别,并基于条件随机场CRF进行实体边界识别,最后采用自适应感知机算法实现了对实体的自动分类,取得了不错的效果。
但是随着互联网中内容的动态变化,采用人工预定义实体分类体系的方式已经很难适应时代的需求,因此提出了面向开放域的实体识别和分类研究。
在面向开放域的实体识别和分类研究中,不需要(也不可能)为每个领域或者每个实体类别建立单独的语料库作为训练集。因此,该领域面临的主要挑战是如何从给定的少量实体实例中自动发现具有区分力的模型。
一种思路是根据已知的实体实例进行特征建模,利用该模型处理海量数据集得到新的命名实体列表,然后针对新实体建模,迭代地生成实体标注语料库。
另一种思路是利用搜索引擎的服务器日志,事先并不给出实体分类等信息,而是基于实体的语义特征从搜索日志中识别出命名实体,然后采用聚类算法对识别出的实体对象进行聚类。
对于具有周期性的时序数据而言,应考虑将一整个周期视为一个实体。
4.2 关系抽取(Relation Extraction)
文本语料经过实体抽取,得到的是一系列离散的命名实体,为了得到语义信息,还需要从相关的语料中提取出实体之间的关联关系,通过关联关系将实体(概念)联系起来,才能够形成网状的知识结构,研究关系抽取技术的目的,就是解决如何从文本语料中抽取实体间的关系这一基本问题。
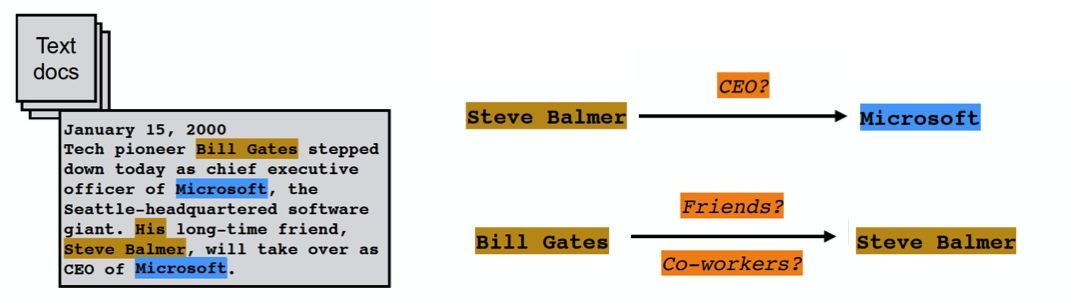
- 人工构造语法和语义规则(模式匹配)
- 统计机器学习方法
- 基于特征向量或核函数的有监督学习方法
- 研究重点转向半监督和无监督
- 开始研究面向开放域的信息抽取方法
- 将面向开放域的信息抽取方法和面向封闭领域的传统方法结合
4.3 属性抽取(Attribute Extraction)
属性抽取的目标是从不同信息源中采集特定实体的属性信息。例如针对某个公众人物,可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。属性抽取技术能够从多种数据来源中汇集这些信息,实现对实体属性的完整勾画。
- 将实体的属性视作实体与属性值之间的一种名词性关系,将属性抽取任务转化为关系抽取任务。
- 基于规则和启发式算法,抽取结构化数据
- 基于百科类网站的半结构化数据,通过自动抽取生成训练语料,用于训练实体属性标注模型,然后将其应用于对非结构化数据的实体属性抽取。
- 采用数据挖掘的方法直接从文本中挖掘实体属性和属性值之间的关系模式,据此实现对属性名和属性值在文本中的定位。
5 知识融合
通过信息抽取,我们就从原始的非结构化和半结构化数据中获取到了实体、关系以及实体的属性信息。
如果我们将接下来的过程比喻成拼图的话,那么这些信息就是拼图碎片,散乱无章,甚至还有从其他拼图里跑来的碎片、本身就是用来干扰我们拼图的错误碎片。
拼图碎片(信息)之间的关系是扁平化的,缺乏层次性和逻辑性;
拼图(知识)中还存在大量冗杂和错误的拼图碎片(信息)
那么如何解决这一问题,就是在知识融合这一步里我们需要做的了。知识融合包括2部分内容:实体链接,知识合并
5.1 实体链接
实体链接(entity linking):是指对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。
其基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象。
研究历史:
- 仅关注如何将从文本中抽取到的实体链接到知识库中,忽视了位于同一文档的实体间存在的语义联系。
- 开始关注利用实体的共现关系,同时将多个实体链接到知识库中。即集成实体链接(collective entity linking)
实体链接的流程:
- 从文本中通过实体抽取得到实体指称项。
- 进行实体消歧和共指消解,判断知识库中的同名实体与之是否代表不同的含义以及知识库中是否存在其他命名实体与之表示相同的含义。
- 在确认知识库中对应的正确实体对象之后,将该实体指称项链接到知识库中对应实体。
- 实体消歧:专门用于解决同名实体产生歧义问题的技术,通过实体消歧,就可以根据当前的语境,准确建立实体链接,实体消歧主要采用聚类法。其实也可以看做基于上下文的分类问题,类似于词性消歧和词义消歧。
- 共指消解:主要用于解决多个指称对应同一实体对象的问题。在一次会话中,多个指称可能指向的是同一实体对象。利用共指消解技术,可以将这些指称项关联(合并)到正确的实体对象,由于该问题在信息检索和自然语言处理等领域具有特殊的重要性,吸引了大量的研究努力。共指消解还有一些其他的名字,比如对象对齐、实体匹配和实体同义。
5.2 知识合并
在构建知识图谱时,可以从第三方知识库产品或已有结构化数据获取知识输入。
常见的知识合并需求有两个,一个是合并外部知识库,另一个是合并关系数据库。
将外部知识库融合到本地知识库需要处理两个层面的问题:
数据层的融合,包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,造成不必要的冗余
通过模式层的融合,将新得到的本体融入已有的本体库中
然后是合并关系数据库,在知识图谱构建过程中,一个重要的高质量知识来源是企业或者机构自己的关系数据库。为了将这些结构化的历史数据融入到知识图谱中,可以采用资源描述框架(RDF)作为数据模型。业界和学术界将这一数据转换过程形象地称为RDB2RDF,其实质就是将关系数据库的数据换成RDF的三元组数据。6. 知识加工
在前面,我们已经通过信息抽取,从原始语料中提取出了实体、关系与属性等知识要素,并且经过知识融合,消除实体指称项与实体对象之间的歧义,得到一系列基本的事实表达。
然而事实本身并不等于知识。要想最终获得结构化,网络化的知识体系,还需要经历知识加工的过程。
知识加工主要包括3方面内容:本体构建、知识推理和质量评估。
6.1 本体构建
本体(ontology)是指工人的概念集合、概念框架,如“人”、“事”、“物”等。
本体可以采用人工编辑的方式手动构建(借助本体编辑软件),也可以以数据驱动的自动化方式构建本体。因为人工方式工作量巨大,且很难找到符合要求的专家,因此当前主流的全局本体库产品,都是从一些面向特定领域的现有本体库出发,采用自动构建技术逐步扩展得到的。
自动化本体构建过程包含三个阶段:
- 实体并列关系相似度计算
- 实体上下位关系抽取
- 本体的生成
比如对下面这个例子,当知识图谱刚得到“阿里巴巴”、“腾讯”、“手机”这三个实体的时候,可能会认为它们三个之间并没有什么差别,但当它去计算三个实体之间的相似度后,就会发现,阿里巴巴和腾讯之间可能更相似,和手机差别更大一些。
这就是第一步的作用,但这样下来,知识图谱实际上还是没有一个上下层的概念,它还是不知道,阿里巴巴和手机,根本就不隶属于一个类型,无法比较。因此我们在实体上下位关系抽取这一步,就需要去完成这样的工作,从而生成第三步的本体。
当三步结束后,这个知识图谱可能就会明白,“阿里巴巴和腾讯,其实都是公司这样一个实体下的细分实体。它们和手机并不是一类。”
6.2 知识推理
在我们完成了本体构建这一步之后,一个知识图谱的雏形便已经搭建好了。但可能在这个时候,知识图谱之间大多数关系都是残缺的,缺失值非常严重,那么这个时候,我们就可以使用知识推理技术,去完成进一步的知识发现。
我们可以发现:如果A是B的配偶,B是C的主席,C坐落于D,那么我们就可以认为,A生活在D这个城市。
根据这一条规则,我们可以去挖掘一下在图里,是不是还有其他的path满足这个条件,那么我们就可以将AD两个关联起来。除此之外,我们还可以去思考,串联里有一环是B是C的主席,那么B是C的CEO、B是C的COO,是不是也可以作为这个推理策略的一环呢?
当然知识推理的对象也并不局限于实体间的关系,也可以是实体的属性值,本体的概念层次关系等。
推理属性值:已知某实体的生日属性,可以通过推理得到该实体的年龄属性;
推理概念:已知(老虎,科,猫科)和(猫科,目,食肉目)可以推出(老虎,目,食肉目)
这一块的算法主要可以分为3大类,基于逻辑的推理、基于图的推理和基于深度学习的推理。6.3 质量评估
质量评估也是知识库构建技术的重要组成部分,这一部分存在的意义在于:可以对知识的可信度进行量化,通过舍弃置信度较低的知识来保障知识库的质量。
7. 知识更新
从逻辑上看,知识库的更新包括概念层的更新和数据层的更新。
概念层的更新是指新增数据后获得了新的概念,需要自动将新的概念添加到知识库的概念层中。
数据层的更新主要是新增或更新实体、关系、属性值,对数据层进行更新需要考虑数据源的可靠性、数据的一致性(是否存在矛盾或冗杂等问题)等可靠数据源,并选择在各数据源中出现频率高的事实和属性加入知识库。
知识图谱的内容更新有两种方式:- 全面更新:指以更新后的全部数据为输入,从零开始构建知识图谱。这种方法比较简单,但资源消耗大,而且需要耗费大量人力资源进行系统维护;
- 增量更新:以当前新增数据为输入,向现有知识图谱中添加新增知识。这种方式资源消耗小,但目前仍需要大量人工干预(定义规则等),因此实施起来十分困难。
8. 总结
通过知识图谱,不仅可以将互联网的信息表达成更接近人类认知世界的形式,而且提供了一种更好的组织、管理和利用海量信息的方式。目前的知识图谱技术主要用于智能语义搜索、移动个人助理(Siri)以及深度问答系统(Watson),支撑这些应用的核心技术正是知识图谱技术。
在智能语义搜索中,当用户发起查询时,搜索引擎会借助知识图谱的帮助对用户查询的关键词进行解析和推理,进而将其映射到知识图谱中的一个或一组概念之上,然后根据知识图谱的概念层次结构,向用户返回图形化的知识结构,这就是我们在谷歌和百度的搜索结果中看到的知识卡片。
在深度问答应用中,系统同样会首先在知识图谱的帮助下对用户使用自然语言提出的问题进行语义分析和语法分析,进而将其转化成结构化形式的查询语句,然后在知识图谱中查询答案。比如,如果用户提问:『如何判断是否感染了埃博拉病毒?』,则该查询有可能被等价变换为『埃博拉病毒的症状有哪些?』,然后再进行推理变换,最终形成等价的三元组查询语句,如(埃博拉,症状,?)和(埃博拉,征兆,?)等。如果由于知识库不完善而无法通过推理解答用户的问题,深度问答系统还可以利用搜索引擎向用户反馈搜索结果,同时根据搜索结果更新知识库,从而为回答后续的提问提前做出准备。
文章综合自
- https://www.cnblogs.com/huangyc/p/10043749.html
- C. Peng, Y. Sheng, W. Gui, Z. Tang, and C. Li, “A Rolling Bearing Fault Diagnosis Method Based on Multimodal Knowledge Graph,” IEEE Trans. Ind. Inf., pp. 1–11, 2024, doi: 10.1109/TII.2024.3431074.
-

海淘氪金不求人——申领国际卡组织银行卡
Introduce
在文章正式开始之前,先介绍一下卡组织相关的背景知识。卡组织全称银行卡转接清算机构(又称信用卡组织/银行卡组织),由成员组成的国际性或区域性支付卡组织,授权成员发卡,受理商户的卡交易,拥有并经营自己的国际区域处理网络。卡组织负责建设和运营全球或区域统一的支付卡信息交换网络,负责支付卡交易的信息转换和资金清算,制定并推行支付卡跨行交易业务规范和技术标准。简而言之其作用就是银行卡可以跨行交易,对于支付宝/微信这种第三方支付,只需要和卡组织对接即可,不需要和每一家银行单独谈判。在中国大陆,最常见的卡组织即为银联,我们可以在绝大多数银行卡正面的右下角看到他的身影。

笔者的洛天依小柠檬卡,右下角可见银联标识 为什么需要国际卡组织的卡?
随着中国实力和影响力的不断提升,我们非常乐见于银联卡在国际上的应用越来越广泛,例如不少国外的线下商场和线上电商如亚马逊均支持银联卡支付。但由于银联卡的发行区域主要为中国,一些不面向中国人或主要交易对象不为中国人的网站便不会接入银联网络,因此我们需要一张国际卡组织的银行卡使得我们能顺利剁手。
国际卡组织银行卡的用处
1.Google play应用内购,可以用来购买GPT Plus(Apple会验证发卡国,因此不可用)
2.境外线下/线上消费
3.部分地区的地铁拍卡入闸
国内银行发行的国际卡介绍
本文主要围绕借记卡展开介绍,因为相关信用卡产品有够多,银行也非常乐意给你介绍信用卡。本文只介绍笔者十分了解甚至在用的银行卡。

万事达
万事网联由万事达卡和网联清算公司合资成立,于2023年11月17日获得由中国人民银行核发的银行卡清算业务许可证。自此,万事达可在中国内地发行以人民币结算的银行卡。但由于万事网联刚刚起步,有银行发行的万事达人民币卡甚至无法境外线上交易,因此本文不对万事网联多做介绍,只介绍万事达卡。
中国银行

跨境通MC白金1.免年费
2.免货币转换费
3.World
4.bin 538113线下申请 
跨境通MC金1.免年费
2.免货币转换费
3.Gold
4.bin 529774线下申请  莫奈日出印象
莫奈日出印象1.免年费
2.免货币转换费
3.World
4.bin 5332281.线下申请
2.上海分行网申
3.网申进度查询
4.官网介绍
5.活动介绍通过链接线上申请的卡只能寄到选定的上海开户网点,须本人去领卡激活。
非人哉白泽小玉1.免年费
2.免货币转换费
3.Gold
4.bin 5297741.线下申请
2.上海分行网申
4.官网介绍1.无人民币账户,需要中行银联 1 类卡购汇(通过app操作)后转入才可使用,跨境通卡支持 19 种外币
2.每人最多只能持有 4 张中行借记卡
3.无法在中国大陆地区的商户交易
4.支持 3ds 验证,支持绑定 Paypal
5.在线支付时,仅校验卡号、有效期、CVV2,不校验持卡人姓名,不校验密码。持卡人姓名可填写 BOC DEBIT,账单地址可随意填写,不支持 AVS 系统验证
6.外币借记卡不受一二类户管理,中行外币借记卡支持范围最广
VISA
笔者还真没办过visa的借记卡,倒是有工商银行的visa信用卡。可以尝试办理工行奋斗简约白金/金卡,在申请日本签证时部分领区可以替代资产证明申请。

美国运通
2020年8月28日,美国运通与连连数字科技有限公司的合资企业——连通(杭州)技术服务有限公司(以下简称“连通公司”)已在中国境内正式开始商业运营。和万事网联一样,该卡使用人民币结算,外币由运通内部汇率换算后以人民币入账。

兴业银行美国运通®标准借记卡1.免年费
2.免收每月前3笔境内跨行ATM取现手续费
3.免收兴业银行电子渠道人民币跨行转账手续费1.线下办理
2.申请链接1.连通卡可以绑定支付宝/微信/云闪付,但不能在云闪付内转账,可以在中国大陆交易
2.相较于万事达和visa,美国运通的支持网站较少,例如Azure就不支持
3.运通是目前使用最方便的国际卡组织借记卡了,只需存入人民币,无须购汇。但汇率不透明,货币转换费也没有明确表示是否收取。但就笔者本人使用而言,与中行汇率相差不大
JCB
JCB为日本的卡组织,在中国国内貌似只有信用卡发行。有消息称,使用中国发行的JCB卡可绑定AppStore日区
用卡注意
- 除美国运通和万事网联以外,均需有一张相同银行的一类银联卡用于购入外汇,转账进外币卡后使用(免转账费)
- 借记卡绑定境外平台时请确保卡内有一定余额。境外平台会先扣款确定卡的可用性再退款
- 境外平台消费时,一般是先冻结实际消费金额的102%,一段时间后再实际扣款(100%)。实际扣款之前,消费记录不可查
- 请保护好卡信息(卡号、有效期、安全码)。境外平台不会验证手机号,有以上三要素足以盗刷你的银行卡。