1.LLM时序分析面临挑战
- 第一个挑战是知识可迁移性。时间序列数据具有季节性和趋势性,同时包含随机性或噪声。由于分布偏移,这些特征在不同领域或同一领域的不同时间可能差异显著,增加了模型或时间序列表示迁移的难度。
- 第二个挑战与数据稀疏性有关。传统时间序列数据集因按日、月或年收集而稀疏,且受隐私限制,如心电图分类数据获取困难。数据稀缺性限制了深度学习模型的有效训练,现有数据集往往不足以支持高质量模型学习。
- 第三个挑战与多模态学习有关。在多模态时间序列分析中,整合不同模态数据可提升模型性能和可解释性。例如,股票走势预测中整合社交媒体信息可提高预测精度。但将不同频率或间隔的多模态数据对齐以反映时间关系具有挑战性,且不同模态需不同技术捕获信息,整合这些信息至连贯模型复杂。
- 最后,可解释性也是高度需要的。模型生成预测或识别模式的详细解释能显著提升时间序列的效用和可接受性。例如,公用事业公司需向监管机构和消费者证明其能源需求预测模型的决策合理性。然而,现有时间序列模型多为黑盒,缺乏对模型行为或预测的解释。
2.时序数据
就通道数而言,时间序列数据可分为单变量时间序列和多变量时间序列。对于长度为 T 的单变量时间序列样本 $X = \lbrace x_t \rbrace_{t \in \lbrace 1, \dots, T\rbrace} \in \mathbb{R}$
,$x_t$是在时间戳 t 采集到的时间信号。对于具有N维的多变量时间序列样本$ X=\lbrace x_t \rbrace_{t\in {1,…T}} \in \mathbb{R}^{N\times T}$ ,每条记录$x_t$是特定时间戳 t 的信号。
要处理多元时间序列的不同通道,有两种常用的策略[112]:通道混合和通道独立。在通道混合策略中,时间序列模型将首先把多个通道投射到隐空间中进行通道融合。在通道独立策略中,模型将单独处理不同的信道,这表明所有信道共享同一个模型。与投影器取决于多元时间序列通道数量的通道混合相比,通道独立配置可以轻松处理具有不同通道的时间序列。因此,信道无关性被广泛应用于带有域转移或模型预训练的时间序列分析。 一般来说,主流的时间序列分析任务包括时间序列分类、时间序列预测、时间序列估算和时间序列异常检测(如图所示)

TS(Time-series)数据具有以下属性:
- Temporal Dependency:按不同时间戳收集的时间序列数据本身就具有时间依赖性。过去的观测结果可作为预测未来值的指标。因此,时间序列分析模型通常需要将时间序列的子序列作为输入,以有效辨别这些潜在的时间关系。例如,在各种实际情况下,时间序列数据会表现出非平稳性和季节性等特征。 非平稳性指的是序列的统计属性,如其分布随时间而变化。这种可变性给预测带来了复杂性,因为在数据生成过程发生变化的情况下,过去的趋势可能不会持续下去.季节性是时间依赖性的另一个重要方面,它包括在固定时间间隔内(每天、每周、 每月或每年)发生的一致且可预测的波动。识别和理解季节性可以将这些周期性模式和一些时间戳信息纳入预测,从而改进对数据的理解和分析,从而增强建模过程。
- Spatial Dependency:对于多变量时间序列数据,单个时间序列可以代表复杂系统的不同实体。序列间的关系被称为空间依赖性,对于整体系统建模至关重要。 一方面,多元时间序列中的某些变量可能无法为模型构建提供充足的信息。另一方面,有效的空间依赖性建模对于揭示时间序列数据中隐藏的模式至关重要。
- Semantics Diversity:Unlike image and text data, where consistent semantics can often be found across different domains (with each word or visual patch representing similar meanings in various sentences or images), time series data lacks this uniformity. Identical subsequences or shapelets in time series datasets can represent entirely different concepts depending on the context. This variability complicates the process of learning representations and transferring models in time series analysis, presenting unique challenges to accurately interpret and utilize the data. (相同/相近的趋势在不同背景下反映的情况不一样)
3.预训练基础模型的关键阶段
基础模型(foundation model)是指在大规模、多样化数据集上训练后,通过微调适应多种下游任务的模型。这些模型源自深度学习,结合了自我监督学习和迁移学习,随着规模增大,展现出强大的零次/少次学习及链式思考推理能力,尤其在NLP和CV领域表现突出。与LLM专精与NLP不同,基础模型在多领域均有应用。
传统时间序列分析因数据不足,难以训练复杂模型,因此社区期待基础模型能在有限数据上展现优异性能。尽管NLP和CV领域的基础模型发展迅速,但基于时间序列的基础模型较少,主要因数据集规模小。不过,已有如ForecastPFN、TimeGPT等模型出现,表1提供了这些模型的比较。
| Model | Parameter Size | Transformer Mode | Channel Setting | Task Type | Pre-trained Dataset | Data Size |
|---|---|---|---|---|---|---|
| ForecastPFN | – | Encoder-only | Uni. | Fore. | Synthetic Data | – |
| TimeGPT | – | Encoder-decoder | Uni. | Fore. | – | 100 B time points |
| TimesFM | 225M | Decoder-only | Uni. | Fore. | Google Trends, Wiki Pageviews, Synthetic Data | 101 B time points |
| Lag-Llama | – | Decoder-only | Uni. | Fore. | Monash | 0.3 B time points |
| TimeCLR | – | Encoder-only | Uni. | Class. | UCR | – |
| GTT | 57M | Encoder-only | Multi. | Fore. | – | 2.4 B time points |
3.1 数据处理
3.1.1 数据收集
大语言模型(LLMs)的泛化能力得益于大规模、高质量的文本预训练。同样,时间序列分析中,广泛且高质量的数据对构建有效基础模型至关重要。
- 数据拆分:在构建遵循标准协议的基础模型时,预训练数据集被分为训练集和验证集。在微调阶段,模型会接触到在预训练阶段未见过的目标数据集,每个数据集进一步被拆分为训练集、验证集和测试集。
-
数据源和规模:在现有的时间序列预测基础模型中,Lag-Llama在Monash时间序列仓库上预训练,GTT收集了180,000个时间序列,TimesFM选择Google趋势等数据源,TimeGPT构建了超过1000亿数据点的仓库,但未公开。
-
数据增强:为了扩大预训练数据集,现有工作采用了各种数据增强技术。Lag-Llama 使用 Freq-Mix 和 Freq-Mask 来生成更多的训练样本以防止过拟合。TimeCLR 采用了数据增强技术(例如抖动、时间扭曲、裁剪)来生成更多数据,使模型对扭曲、不同的噪声类型等具有不变性。ForecastPFN 不是在真实世界的数据上进行预训练,而是在完全合成的数据分布上进行预训练。
-
数据质量:数据质量对于确保模型的有效性至关重要。时间序列数据中常见的挑战包括缺失值、噪声和异常值。为了消除可能导致梯度爆炸的多样异常值,ForecastPFN 首先掩盖缺失值,然后裁剪所有 3σ 异常值。类似地,GTT 通过消除归一化值超过 9 的数据点来消除极端异常值。
3σ准则 3σ准则又称为拉依达准则。 所谓3σ,当数据被定义为在一组测定值中与平均值的σ(标准偏差)超过3倍时,这个值就被认为是异常值,而这个异常值的概率通常小于0.3%,用公式可以理解为p(|x−μ|>3σ)⩽0.003 。
3.1.2 数据对齐
在时序分析中,数据对齐(Data Alignment)是一个关键步骤,尤其是在多变量、多源数据的情况下。数据对齐是指在处理多个时间序列时,将不同来源的数据点依据时间维度进行同步,以便后续的分析、建模和预测工作能够准确地反映各变量之间的相互关系。基础模型在多个异构数据集上预训练,需对齐和平衡以增强泛化能力。时间序列数据的处理面临值范围可变性的挑战,传统的缩放方法不适用。数据对齐的过程通常包括以下几个重要方面:
- 时间戳同步
多个时间序列可能来自不同的数据源或以不同的时间戳记录。因此,第一步是确保所有的时间序列都有一致的时间戳格式,并在统一的时间尺度上进行同步。常见的方法包括:
- 时间戳格式标准化:将所有时间戳转换为相同的格式(如UTC)或单位(秒、分钟、小时等)。
- 对齐采样频率:不同数据源可能有不同的采样频率(如每秒、每分钟、每小时),因此需要调整时间序列的采样频率使其一致。这可以通过插值、降采样或重采样来实现。
- 插值与缺失值填充
在对齐过程中,常常会遇到缺失的数据点,尤其是当两个或多个时间序列的记录频率不同步时。常见的处理方法包括:
- 线性插值:通过两点之间的线性关系来估计缺失的数据点。
- 前向填充和后向填充:用之前或之后的可用值填充缺失值。
- 样条插值:利用多项式或样条函数进行插值,适用于非线性数据。
- 移动平均:通过取前后数据点的均值来填补缺失值,平滑时间序列。
- 时间窗口对齐
有些时间序列的数据可能并非连续记录,而是基于某个特定时间窗口(例如每天、每小时)生成的。这种情况下,数据对齐需要确保每个时间窗口内的数据点能够在不同的序列之间匹配。时间窗口对齐的一些常见方法包括:
- 固定窗口对齐:将所有时间序列数据切分为固定的时间窗口(如1分钟、1小时),并确保每个时间窗口内有可比数据点。
- 滑动窗口对齐:使用滑动窗口的方法,使得窗口的大小固定但窗口的起点是逐步滑动的,适合需要捕捉序列中动态变化模式的场景。
- 可变上下文长度(TimesFM):可变上下文长度指的是模型可以根据数据的特点和变化动态调整处理的时间窗口大小,而不是使用固定的窗口长度。在传统的时序模型中,窗口长度通常是固定的,如滑动窗口、移动平均等。而在 TimesFM 中,上下文窗口的长度可以根据时间序列的特定模式动态变化,这使得模型能够更好地处理数据中的短期波动和长期趋势。
- 数据变化速度:当数据变化较快时(例如金融市场的波动),模型会缩短上下文长度,以便快速捕捉变化。
- 噪声水平:当数据中噪声较多时,TimesFM 会使用较小的窗口进行局部平滑处理;当数据质量较高时,模型会使用较大的窗口平滑整体趋势。
- 卷积平滑:CNN 可以用于捕捉局部模式,通过卷积核大小的变化,实现不同尺度的平滑处理。
- 记忆机制:LSTM 或 Transformer 允许模型记住长时间的历史信息,使其能够根据较长的历史数据进行更复杂的平滑处理。
- 时间滞后(Lag)处理
在某些情况下,不同时间序列之间可能存在因果关系或时间滞后效应。例如,一个序列的变化可能导致另一个序列在数小时或数天后发生变化。这时,可以通过引入滞后项来对齐这些时间序列,以捕捉滞后效应。常见的做法是手动或通过建模寻找最优滞后时间,并将其应用于数据对齐。
- 降采样与升采样
- 降采样(Downsampling):如果一个序列的数据频率较高,可以通过计算平均值、最大值、最小值等方式将其降采样至与其他序列相同的频率。
- 升采样(Upsampling):当一个序列的数据频率较低时,可以通过插值或数据合成的方式升采样,以便与其他高频数据源对齐。
- 数据变换与标准化
有时,在对齐之前,可能需要对不同的时间序列进行标准化或归一化,使它们在相同的尺度上进行对比。这包括:
- 归一化:将数据缩放到[0,1]的范围内,确保不同量纲的数据可以对齐。
- 标准化:将数据转化为均值为0,方差为1的标准正态分布,便于序列的比较。
GTT和Lag-Llama采用特定样本归一化技术提升模型便利性。GTT通过固定通道数和上下文长度处理多通道数据,而TimesFM使用可变上下文长度实现数据平衡。模型对齐的关键措施包括值缩放、处理输入输出长度变化、管理多通道数据和实施平衡采样,这些对稳定训练和防止性能下降至关重要。
3.2 架构设计
3.2.1 Backbone for Foundation Model.
A deep learning model can serve as the basis for a foundation model, provided that its size can be scaled up. Scaling is indeed crucial for developing remarkably successful LLMs Due to transformer architecture’s outstanding capacity for parallelization, it allows scaling to a massive number of parameters, making it the preferred backbone for LLMs.
In the context of time series analysis, TimeCLR compares several backbone models, including GRU, LSTM, ResNet, and transformer, and finds that the transformer outperforms the alternatives. Ultimately, all the existing foundation models choose transformers as their backbone models. The key differences among these transformer-based foundation models lie in the transformer mode, input tokenization, and predictive objects. We will continue the discussion and comparisons in the following. Note that additional potential architectures have been suggested in, including Transformer++ and State-Space Models.
3.2.2 Transformer Mode.
Transformer 模型包括编码器和解码器,有三种模式:仅编码器(如BERT)、仅解码器(如GPT系列)和编码器-解码器(如BART和T5)。仅解码器模型在零样本和少样本学习中表现出色,GPT-3是典型例子。仅编码器模型适合处理整个输入序列的任务,如分类和情感分析,而解码器模型适用于顺序生成任务,如文本生成。编码器-解码器模型因其输入输出分离在复杂任务中占优。GTT和ForecastPFN为时间序列预测开发了仅编码器模型,而TimesFM和Lag-Llama选择解码器模式。TimeGPT采用编码器-解码器模式以处理复杂数据。
3.2.3 Channel Setting.
Another issue relevant to the architecture design of time series foundation models is the channel setting, specifically channel-independence and channel-mixing. Channel-independence refers to accept univariate sequence input while channel-mixing involves the utilization of multivariate sequence input. These different channel settings result in varied tokenization approaches for time sequences and necessitate distinct model designs.
通道独立:单变量模型设计相对简单,因为多变量数据的通道数可能变化。多数研究倾向于使用通道独立,通过不同的技术如PatchTST、TimesFM、Lag-Llama和TimeCLR将单变量序列转换为向量序列。
通道混合:将多变量序列分解为多个单变量序列可能会忽略不同通道/变量之间的关系和相互作用。GTT为时间序列预测建立了一个多变量基础模型。他们将渠道变量重塑为批量大小,从而得到单变量序列,并将其切成片段。在推理阶段,由于通道变量已与批量大小融合,因此模型可以接受不同的通道数。
4 使LLM处理时序数据的方法
有两种时间序列的LLM适应范式:(a)嵌入可见大语言模型,通过重新设计LLM直接感知时间序列嵌入来适应时间序列任务。(b)文本可见大语言模型,通过以句子对句子的方式制定时间序列的输入-输出来适应时间序列任务。
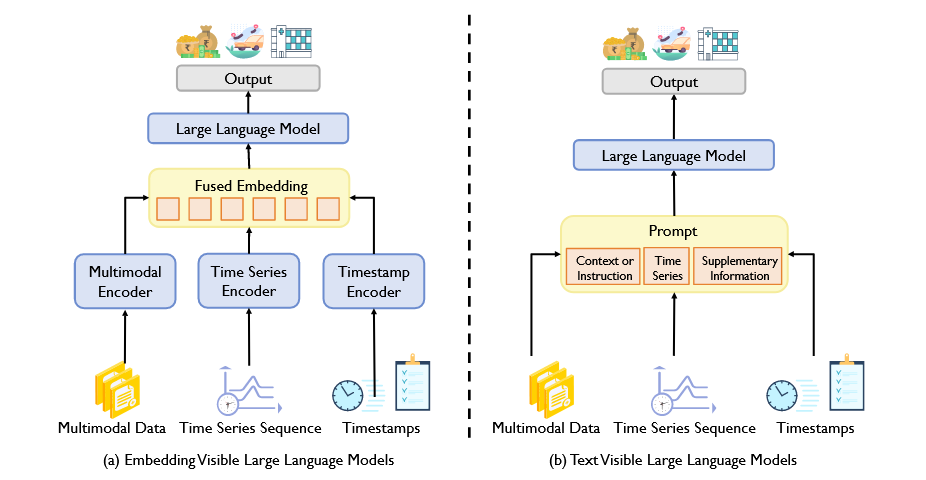
这两种范式在输入-输出方式、LLM利用和数据融合上有所不同。LLM不仅用于预测,还可作为增强器、数据生成器和解释器,扩展了其在多种应用中的功能。本节将介绍关键概念,分析各范式的关键阶段,并探讨LLM在时间序列问题中的多重角色。
01、嵌入可见的LLM调整
嵌入可见的LLM调整利用传统的 “预训练和微调” 范式重新设计LLM,并将其微调用于下游时间序列任务。在这个范式下,LLM被重新设计为直接感知时间序列嵌入,而不是传统的文本输入。
(1)向量化的时间序列表示
在时间序列分析中应用LLM时,首先需将时间序列数据转换为LLM可处理的向量序列。在嵌入可见的LLM调整中,时间序列被向量化,LLM被重新设计以直接感知这些时间序列嵌入。受Transformer模型分块策略的启发,研究者将时间序列切分为固定长度的块,作为LLM的输入标记,以保留局部语义信息。对于多变量时间序列,常分解为单变量序列后进行分块处理。然而,TEST模型在通道混合设置下处理时间序列,强调不应忽视跨变量的依赖关系。
(2)时间序列和LLM之间的语义空间对齐
时间序列转换为向量序列后,需解决与LLM认知嵌入空间的模态差距。研究者通过重新设计输入嵌入层并在特定数据集上微调LLM,以对齐时间序列与LLM的维度空间。Time-LLM和TEST等研究使用文本原型重新编程嵌入,通过对比学习和多头注意力层,使时间序列特征与语言元素对齐,以增强LLM对时间序列的理解。
(3)时间序列的特性和模式识别
时间序列与自然语言在模式和属性上有本质差异,这给LLM应用于时间序列任务带来挑战。时间序列的独特特征包括多变量依赖、分布偏移和复杂时间模式。尽管基于Transformer的模型在某些任务中表现出色,但它们可能忽视时间序列的独特属性,如趋势和季节性。研究表明,时间序列Transformer在鲁棒性上可能不如其他模型,且LLM在预训练阶段缺乏识别时间序列特性的能力。因此,在应用LLM于时间序列分析时,考虑这些特性至关重要。
- 时间模式:TEMPO方法将单变量序列分解为趋势、季节和残差,简化了LLM的预测,并通过可学习的提示池编码共享时间模式。分解后的部分经过归一化、补丁化和嵌入,与提示一起输入GPT模块。实验验证了分解和提示池的有效性。AuxMobLCast在编码器-解码器架构中加入辅助POI分类模块,以识别与不同POI类别相关的访问模式,消融研究显示此模块显著提升了BERT编码器的性能。
- 多变量依赖性:时间序列数据常为多变量,如股票价格和ECG数据,而文本是单变量的。许多研究将LLM调整为处理多变量时间序列,但TEST指出通道独立性方法忽略了多变量依赖性。TEST直接处理多变量时间序列,将其切片成不同长度的标记,输入编码器生成时间嵌入,以捕捉变量间的相互依赖。
- 时间戳信息:研究表明,在基于Transformer的模型中加入时间戳信息,如在疾病预测和交通流量预测中,能提升模型性能。LLM4TS为每个时间序列补丁分配初始时间戳,编码时间属性并融合成时间嵌入,与标记和位置嵌入结合生成最终嵌入。
- 分布偏移:FPT和TEMPO采用反向实例归一化(RevIN)对单变量输入序列进行归一化,以减轻分布偏移并促进知识传递。然而,LLM4TS指出RevIN的可训练仿射变换不适用于自回归模型如GPT-2,因此在监督微调阶段使用标准实例归一化。
(4)多模态数据融合
多模态学习在NLP和CV领域广泛研究,如视觉问答和图像-文本生成。时间序列分析中也存在多模态场景,如金融和医疗数据集可能包含文本或图像信息。时间序列数据的抽象性使得语义挖掘和知识传递具有挑战性,但通过多模态信息补充可以增强模型对复杂时间模式的学习,提升表示能力、泛化能力和可解释性。受多模态LLM成功的启发,研究者设计了用于时间序列分析的多模态模型,根据信号粒度分为两类。
(5)样本级多模态融合
研究者利用多模态信号如文本报告来丰富时间序列样本的细节,增强内部知识。METS结合ECG信号与临床报告,使用ClinicalBert模型提取诊断知识,指导ECG编码器训练。TEMPO则结合季度新闻和报告,预测财务指标,并利用时间嵌入和软提示提取摘要信息。这些方法通过多模态信息提升时间序列分析的深度和准确性。
(6)任务级多模态融合
另一研究方向利用多模态知识提升模型泛化能力和跨数据集知识传递,涉及任务或领域级别。UniTime通过领域指令帮助模型识别数据源并调整预测策略,指令以句子形式包含领域知识,与时间嵌入融合。Time-LLM采用Prompt-as-Prefix技术,使用包含领域知识、任务指令和数据统计的提示增强时间序列表示,促进LLM的推理和模式识别。
(7)微调
微调预训练的LLM对于其在特定任务中的应用至关重要,涉及重新配置输入/输出层和目标函数。UniTime通过完全微调GPT-2在跨领域时间序列预测中取得最佳性能,但全参数更新可能导致灾难性遗忘和资源需求增加。为解决这些问题,研究如FPT、TEMPO和LLM4TS采用部分参数更新,而TEST和TimeLLM则使用冻结LLM结合可学习软提示。这些方法旨在减少参数更新,同时保持性能,并需对齐时间序列嵌入与LLM文本空间。此外,通过识别时间模式和整合多模态信息,进一步增强LLM在时间序列分析中的能力。
02、文本可见的LLM调整
文本可见LLM调整遵循 “预训练、提示和预测” 的范式,重新设计时间序列任务,并利用提示技术激活LLM的能力。在这个范式下,时间序列任务的输入-输出对被重新构造为文本提示。
(1)文本化的时间序列表示
在文本可见的LLM调整中,时间序列数据被转换为字符串,以便与提示无缝集成。研究者使用LLM直接推断任务,无需微调,通过句子对句子格式化任务。数值数据被描述为自然语言句子,并结合上下文信息。对于特定任务,如人类移动性预测、健康任务和天气预测,LLM被微调,并以自然语言形式制定任务。
(2)时间序列和LLM之间的语义空间对齐
在将时间序列转化为句子的工作中,LLM通过标记化理解字符串,但原始标记化方法可能不适用于数值,导致连续数值被分割并忽略时间意义,增加算术运算复杂性。LLMTIME建议在标记化前对时间序列进行预处理,如为GPT增加空间技术。提示调整作为一种潜在解决方案,通过添加可训练嵌入优化输入,帮助LLM理解时间序列信息。
(3)时间序列属性和模式识别
与嵌入可见LLM调整下的时间序列特征提取不同,文本可见LLM通过将相关信息集成到提示中来识别时间序列的独特属性和模式。
- 时间模式。 LLM-Mob指出LLM难以直接从复杂停留数据中提取有用信息进行人类移动性预测,因此提出分解数据为历史和上下文序列,以帮助LLM理解长期和短期移动模式。AuxMobLCast发现POI类别与乘客模式相关,通过集成辅助POI分类模块到编码器-解码器架构中,显著提升了BERT编码器的性能。
- 跨序列依赖。为了解决股票预测中的跨序列依赖问题,TDML从相似股票中提供大量示例,以创建上下文学习提示,证明LLM能有效整合跨序列信息。LLMST将所有轨迹整合在一个提示中,以观察模型是否能考虑轨迹间交互,发现这可能提升性能。TWSN利用多个历史股票特征,将多元价格特征转化为表格格式的字符串,并整合到文本提示中,用于股票走势预测。
- 时间戳信息。 UMEF将时间戳信息整合到能源消耗预测模板中。LLM-Mob在人类移动性预测中考虑目标停留时间的时间信息,并通过融入与时间和日期相关的事实引导LLM分析移动模式的变化。AuxMobLCast在移动性提示中包含日期信息,发现删除时间日期信息后性能下降,表明时间戳有助于LLM捕捉时间模式。
(4)多模态数据融合
文本可见的LLM设置中对多模态学习的研究较少。TWSN在样本级多模态数据融合中,结合历史股票价格和推文构建多模态提示,评估ChatGPT在股票走势预测中的能力。任务级多模态数据融合中,任务级信息作为补充添加到提示中,以提升模型性能。
(5)提示
受LLM在NLP中泛化能力的启发,研究者使用提示激活LLM在时间序列任务中的能力,将输入整合到文本提示中,引导LLM生成期望的自然语言输出。提示分为无调参和基于微调两种,前者在零样本/少样本设置下评估性能,无需微调,后者则微调LLM并更新参数。综述中总结了两种方法并讨论了它们的优缺点。
- 无调参提示:研究者通过设计指令提示,利用LLM的内部知识进行零样本/少样本推理,无需参数更新。TDML优化提示结构,发现零样本CoT提示能显著提升性能。TWSN评估ChatGPT在股票预测中的表现,发现CoT技术虽有提升但不及专门方法。LLMF测试PaLM-24B在健康问题上的零样本性能,发现其在数值任务上表现不佳。LLMST和LLM-Mob通过设计提示评估LLM在移动性异常检测中的性能,强调提示工程的重要性。LLMFS发现PaLM在少样本学习中能处理健康数据,但在零样本设置中性能下降。LLMTIME则表明,通过仔细预处理时间序列,LLM可直接作为零样本预测器,无需额外文本信息。
- 基于微调的提示:为了克服仅利用LLM固有知识的局限性,一些研究结合了传统微调和提示,更新LLM参数以适应特定时间序列任务。PromptCast采用指令微调进行通用时间序列预测,设计了零样本基于指令的提示,用于天气、能源和客流量预测。UMEF在能源消耗预测中使用无指令微调,将数据转换为描述性句子。AuxMobLCast利用无指令微调进行人类移动预测,结合移动数据、时间戳和POI信息,微调编码器-解码器架构。LLMFS为健康任务设计了基于问题-回答的提示,冻结LLM并添加可学习提示嵌入,以理解不同任务的时间序列数据。这些方法通过微调和提示结合,提升了LLM在时间序列任务中的性能。
总之,利用提示的研究的关键贡献在于它们针对特定的时间序列场景设计了复杂的提示。为了增强提示的有效性,一些研究还整合了额外的信息,如时间序列特征、替代数据模态和专家知识。像思维链(CoT)这样的技术已经应用于几项工作中,显示出提高模型性能的潜力
5 LLM的可解释性
可解释性是指人类对模型的行为或预测的理解程度,这一直是人工智能和时间序列领域的重要问题。让模型变得透明和可解释,可以让用户理解、适当信任和有效管理在真实世界场景中部署的模。在某些情况下,合格的模型性能虽可以满足大多数要求,但对于那些用户信任、安全、公平和隐私至关重要的关键决策领域,如自动驾驶、医疗保健和金融,缺乏可解释性将阻碍模型的实际应用。解释性的好处远不止于知识发现、模型调试以及解决人工智能系统与人类专家之间的分歧。
虽然某些模型(如决策树)因其简单明了的结构本质上具有可解释性,但大多数模型,尤其是深度学习模型,本质上都是黑箱,其内部工作机制对用户来说是模糊的。为了应对这一挑战,可解释人工智能(XAI)领域致力于开发能让人类理解深度学习模型内部机制或结果的方法。XAI 研究大致可分为两种方法:局部解释和全局解释 。局部解释旨在阐明模型对特定实例做出决定的原因,力求揭示给定输入与其结果之间的因果关系。与此相反,全局解释则致力于揭示模型的整体内部机制,检查所有实例的结构和参数。解释技术还可分为事前方法和事后方法。前置方法直接结合模型结构的可解释性,而后置方法则侧重于在不改变模型底层结构的情况下解释模型行为。
发表回复